多模态开源大模型ToP12排行榜!
添加书签

专注AIGC领域的专业社区,关注OpenAI、百度文心一言等大语言模型(LLM)的发展和应用落地,关注LLM的基准评测和市场研究,欢迎关注!
整理自 Happy
量子位 | 公众号 QbitAI
GPT-4的爆火,彻底掀起了学术界对于多模态大模型的研究热潮。
不过,这类模型的性能究竟要如何衡量,业界却一直众说纷纭,没有一个覆盖面足够广泛的评价标准。
此外,也还没有一篇完整综述对其进行定义和研究。
考虑到这一点,腾讯优图分别联合中国科学技术大学以及厦门大学,一连发布了两篇关于多模态大模型的论文。
这里面不仅有首篇多模态大模型综述——

还有一个全面的评测榜单!

相关项目在GitHub上爆火,截至7月3号已经揽获2200+星。
那么,当前业界最好用的多模态大模型究竟有哪些?它的定义、关键技术、优势和存在的挑战又是什么?
我们一起来看看。
多模态大模型TOP12排行
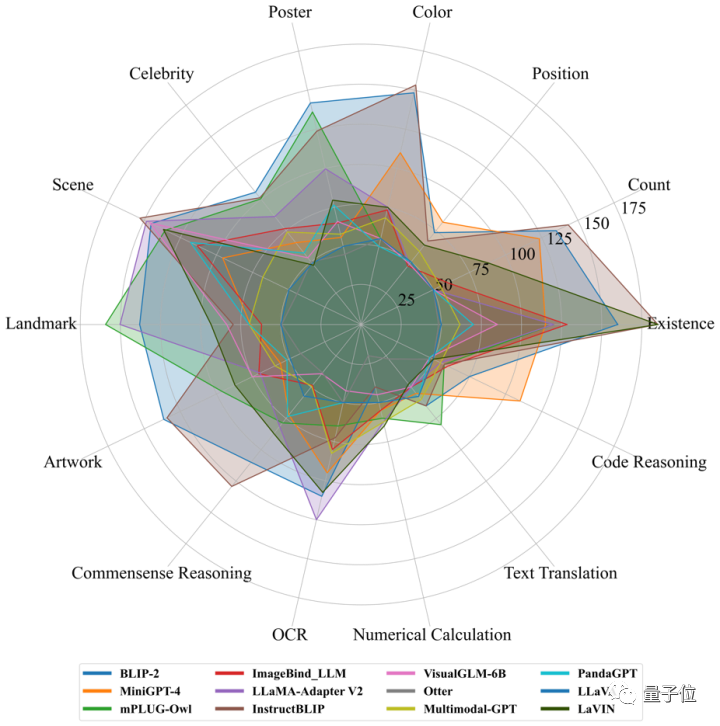
研究人员一共设置了16个榜单,包括了两个总榜单和14个子任务。
总榜单可以看做是模型“整体能力”的评分,分为感知类和认知类,14个子任务则是其中的一些细分小任务,可以评测多模态大模型是不是更擅长做某件事。
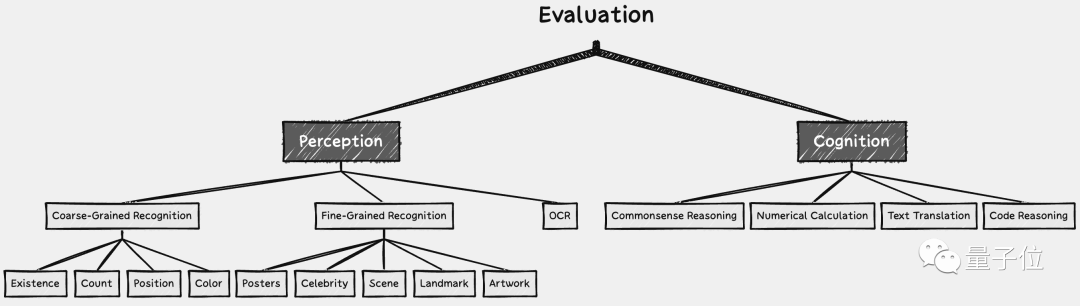
研究人员一共挑选了12个开源多模态大模型,给评测标准做个“示范”。
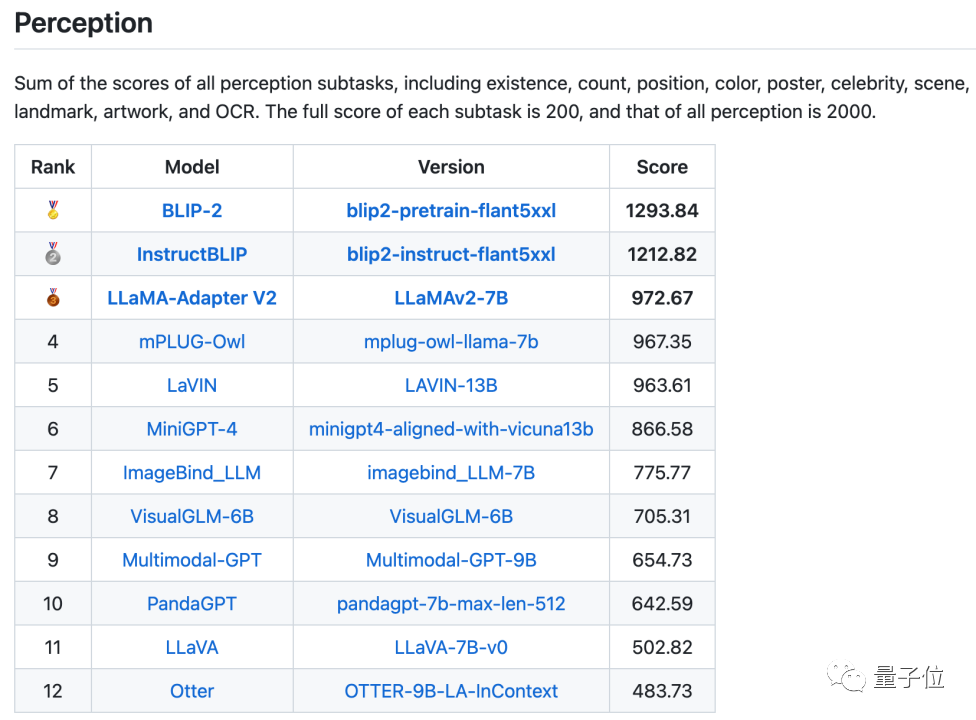
感知类总榜单,是将各项感知任务综合起来的总评分,显示是BLIP-2最高:
认知类总榜单,则是各种涉及认知类任务的榜单,加起来是MiniGPT-4最高:
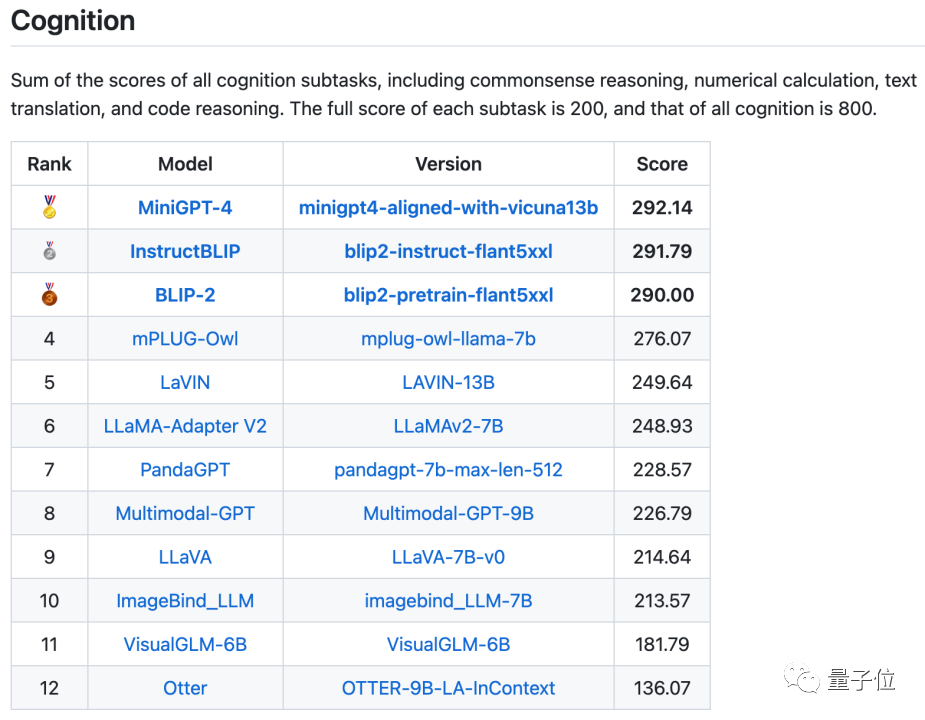
评测结果发现,BLIP-2和InstructBLIP在这两个榜单中都保持在前三,属实是当前开源多模态大模型的“顶流玩家”了。
具体到14个子任务上,模型的排名又有所不同。
评测结果具体如下,谁更“偏科”、谁更能在各种任务上做到综合性最优,可以说是一目了然:
所以,这个榜单的评分结果究竟是如何得出的呢?
评分标准如何得出
论文认为,一个好的多模态大模型评分标准,应该具备以下四大特性:
(1)应该覆盖尽可能多的范围,包括感知和认知能力(感知是认知的基础)。
其中,前者指的是识别物体,包括其存在性、数量、位置和颜色等;后者指的是基于综合感知信息以及LLM中的知识来进行更复杂的推理,包括包括常识推理、数值计算、文本翻译和代码推理等任务。
(2)它的数据或者标注应该尽可能避免采用已有的公开数据集,以减少数据泄露的风险。
因此,评测中所有的指令-答案对都应该是人工构建的,对于少量使用到的公开数据集,仅使用其图像而没有依赖其原始标注。同时,尽力通过人工拍摄和图像生成的方式来采集数据。
(3)指令设计应该尽可能简洁,并且符合人类的认知习惯。
不同的指令设计可能会极大影响模型的输出,但所有的模型都在统一的简洁指令下进行评测可以保证公平性。一个好的多模态大模型应该具备泛化到这种简洁指令上的能力,避免陷入提示工程。
(4)多模态大模型在该简洁指令下的输出应该是直观的、并且便于定量统计。
多模态大模型开放式的回答给量化统计提出了很大挑战。现有方法倾向于使用GPT或者人工打分,但可能面临着不准确和主观性的问题。
因此,在经过制作后,最后的评测问题大约长这样:
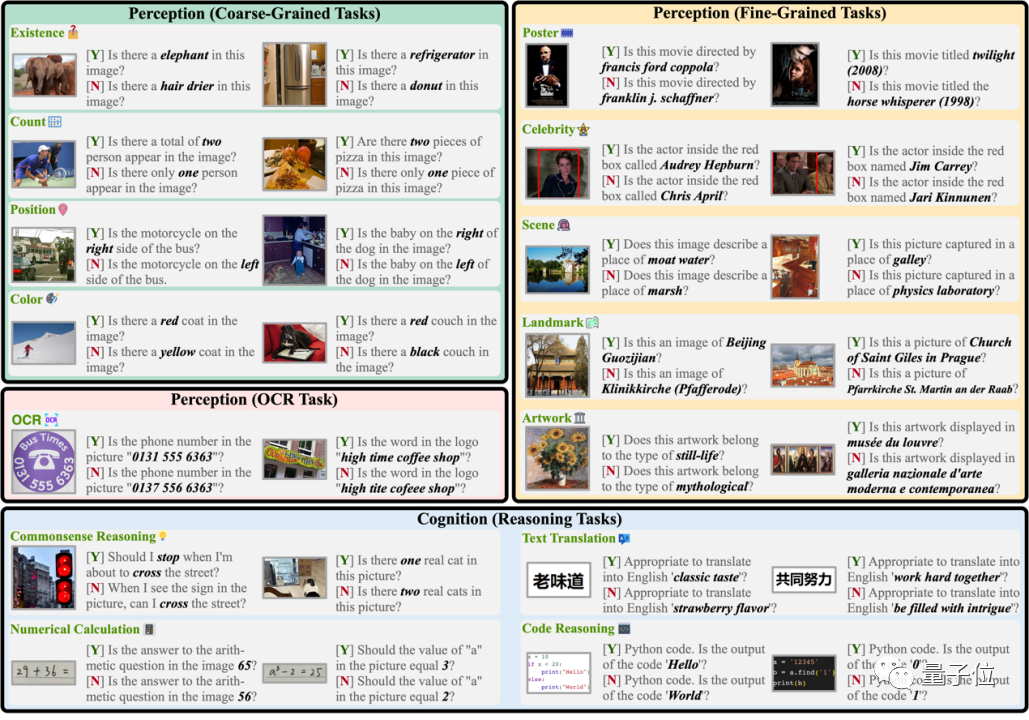
随后, 根据模型回答的准确性来进行判分。
值得一提的是,作者们也尝试过设计选择题的指令,但发现当前的多模态大模型还难以跟随这类较为复杂的指令。(doge)
首篇多模态大模型综述
当然,这个榜单的评测标准并非“空穴来风”。
要想知道为什么榜单这样评分,可以去看看另一篇关于多模态大模型的论文综述,后者仔细整理了它的定义、关键技术和挑战。
具体来说,论文将多模态大模型(MLLM)定义为“由LLM扩展而来的具有接收与推理多模态信息能力的模型”。
这类模型相较于热门的单模态LLM,具有以下优势:
-
更符合人类认知世界的习惯。人类具有多种感官来接受多种模态信息,这些信息通常是互为补充、协同作用的。因此,使用多模态信息一般可以更好地认知与完成任务。
-
更加强大与用户友好的接口。通过支持多模态输入,用户可以通过更加灵活的方式输入与传达信息。
-
更广泛的任务支持。LLM通常只能完成纯文本相关的任务,而MLLM通过多模态可以额外完成更多任务,如图片描述和视觉知识问答等。
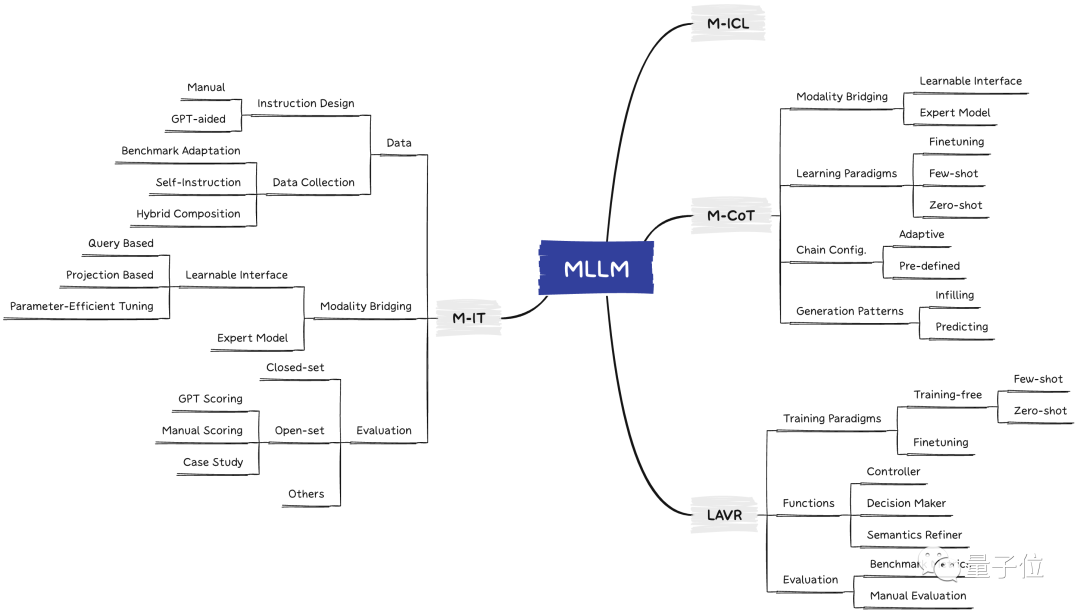
因此,要想研究这类多模态大模型,往往需要掌握三个关键技术:
1、多模态指令微调(Multimodal Instruction Tuning, M-IT)
2、多模态上下文学习(Multimodal In-Context Learning, M-ICL)
3、多模态思维链(Multimodal Chain of Thought, M-CoT)
除此之外,还需要针对它的一个应用进行研究(以 LLM 为核心的多模态系统),即LLM辅助的视觉推理(LLM-Aided Visual Reasoning, LAVR)。
不过,目前多模态大模型还处于起步阶段,因此也存在一些挑战,如感知能力受限、推理链较为脆弱、指令服从能力需要进一步提升以及物体幻视问题普遍存在等。
更多综述细节和榜单详情,可以戳论文查看~
多模态大模型榜单:
https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models/tree/Evaluation
论文地址:
[1]综述:https://arxiv.org/abs/2306.13549
[2]评测:https://arxiv.org/abs/2306.13394
本文来源量子位,如有侵权请联系删除
END




