全球首个专注客服领域GPT,Observe.ai发布300亿参数大语言模型
添加书签

专注AIGC领域的专业社区,关注OpenAI、百度文心一言等大语言模型(LLM)的发展和应用落地,关注LLM的基准评测和市场研究,欢迎关注!
目前,金融、医疗、旅游、证券、法律等行业,相继推出了垂直业务场景的类ChatGPT大语言模型,客户服务领域还处于空白,即便是有也是通过微调方式打造而成。
知名客服平台Observe.AI凭借自己多年客服语料数据和技术沉淀,推出了只专注客服领域完全自研的300亿参数的大语言模型。(申请测试地址:https://www.observe.ai/platform/contact-center-llm)
据悉,该模型可以为客服人员提供自动摘要,例如,客服人员与客户聊了30分钟,可以自动总结姓名、电话号码、用户需求等重点文本内容。Observe.AI表示,其模型总结内容的准确率比GPT-3.5高35%。还提供知识库问答、客服表现分析、情感分析等功能。
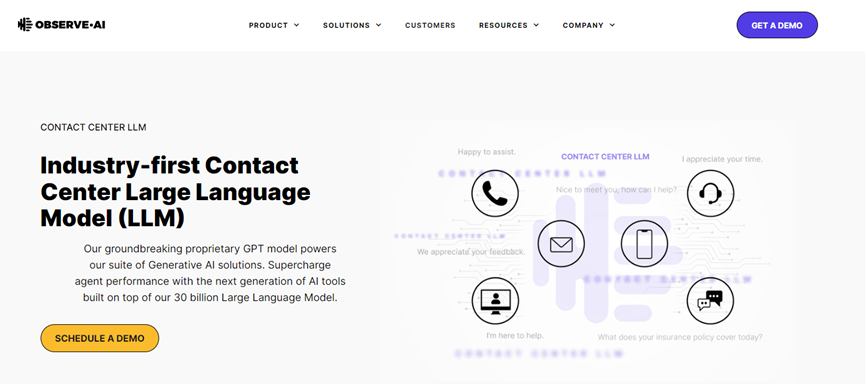
Observe.AI大语言模型功能展示
资料显示,Observe.AI创立于2017年,总部位于美国加利福尼亚旧金山,总融资金额2.13亿美元。Observe.AI曾在2022年4月获得软银领投的1.25亿美元C轮融资,从而晋级行业独角兽。
Observe.AI主要提供AI客服代理、对话数据分析、全渠道客服监控、自动化客服运营等。
ChatGPT等生成式AI产品的火爆出圈,让全球各行业看到了大语言模型的力量。根据Gartner对2,500多名企业高管的调查数据显示,70%表示,将在业务中探索对生成式AI的应用。
因此,Observe.AI推出了专注客服领域的大语言模型,希望借助生成式AI的风口扩大自己的产品影响力和市场份额。
Observe.AI表示,早在2018年便开始试水AI模型将其集成在产品矩阵中,当时使用的是BERT模型,一款由谷歌在2018年发布的预训练深度学习模型。
该模型在大量的无标注文本上进行了预训练,学习了丰富的词汇和句子的表示结构,在文本分类、情感分析、问答系统等业务场景得到了广泛应用。
Observe.AI通过对BERT模型的应用,积累了相当多的预训练方法、数据池和开发经验等,这为日后自研大语言模型奠定了技术基础。
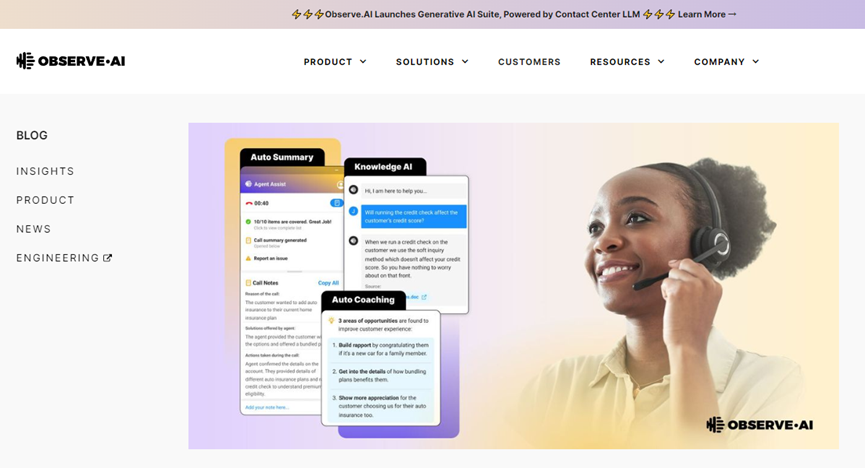
技术方面,Observe.AI推出的300亿参数大语言模型具备高准确率特性,其自动总结文本能力比GPT-3.5高35%,情绪分析能力高33%。Observe.AI表示,ChatGPT等大语言模型一直有一个弊端会生成虚假信息,主要原因之一是在预训练的过程中,使用了大量“黑箱数据”无法确定这些数据的真实性。
Observe.AI在预训练过程中不会使用其他领域的数据,例如,从公开网络抓取的数据,而是使用了纯净的客服领域语料数据。这包括,海量客服日常用语/回答话术,客户常见咨询问题等。
这样做的好处是,可以确保客服人员从大语言模型得到的答案是正确、可靠的。尤其是知识库问答提供的内容,如果内容无法达到超高准确率,那么应用大语言模型将毫无意义。
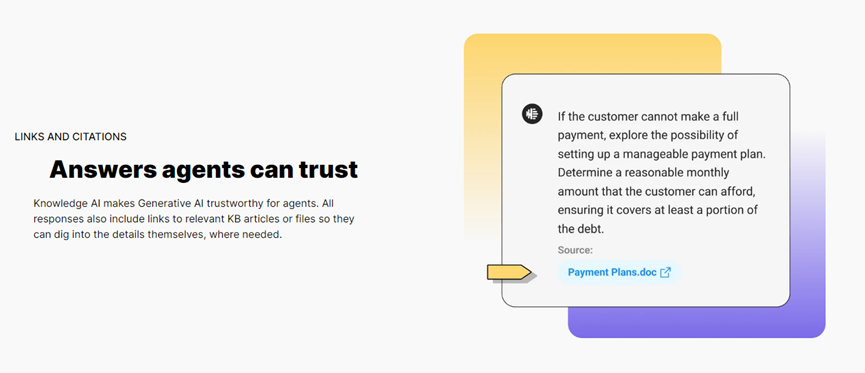
功能方面,Observe.AI主要提供文本自动总结、知识问答库、客服表现自动分析、情感分析等
文本自动总结:与ChatGPT等产品不同的是,Observe.AI可以提供多种类型文本的总结功能。结构化数据总结,用户可以选择通话原因、客户问题、后续解决方案等内容;非结构化数据总结,可以对整个对话内容进行总结。

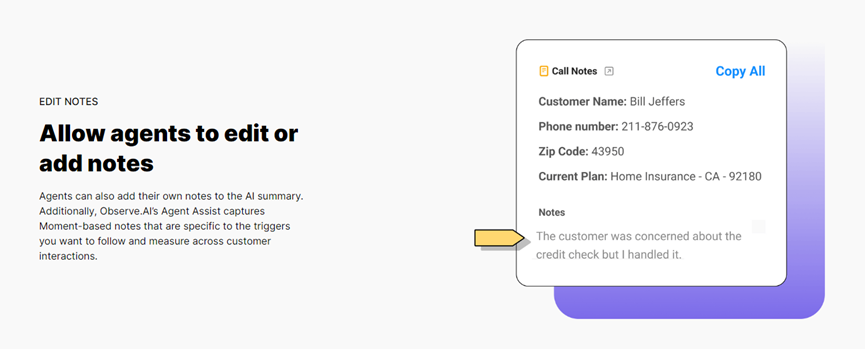
关键字总结:用户可以选择具体的姓名、电话号码、金额、问题等元素。客服人员还可以对总结的内容进行注释。总体来说,Observe.AI提供的总结内容更详细、多元化。
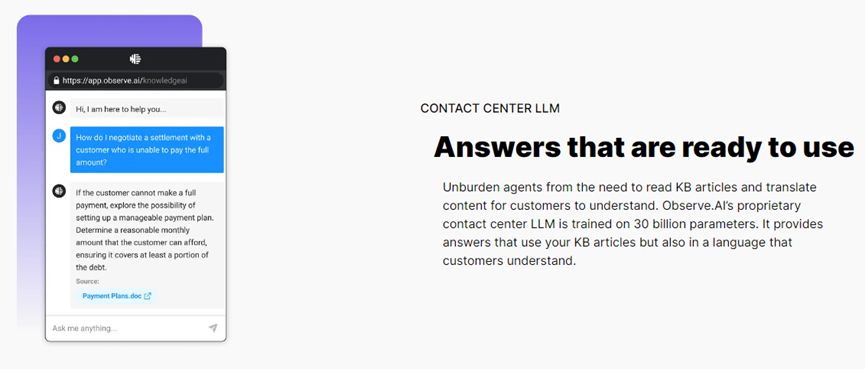
知识库问答:企业通过AI可以轻松将Observe.AI提供的知识库问答功能集成在客服产品中,客服人员通过文本问答方式实时获取专业的知识回答。同时支持用户上传专业的PDF、Word等文档,基于上传内容进行问答。
客服表现自动分析:当客服人员结束服务后,Observe.AI会立刻生成客服人员的表现报告,包括,交互过程中存在哪些弊端、未解决问题、话术问题等。帮助客服人员提升自身的业务水平,更好的服务客户。

Observe.AI认为,客服人员在大语言模型的帮助下,可以大幅度提升工作效率、节省时间,将宝贵时间用在更有商业价值的工作上,从而提升运营效率和销售转化率。未来,将会探索更多大语言模型在客服领域的实际用例。

本文素材来源Observe.AI,如有侵权请联系删除
END




