揭秘GPT-4核心数据:1.8万亿参数,13万亿训练数据
添加书签

专注AIGC领域的专业社区,关注OpenAI、百度文心一言等大语言模型(LLM)的发展和应用落地,关注LLM的基准评测和市场研究,欢迎关注!
7月11日,半导体咨询研究公司SemiAnalysis发布文章,对OpenAI的GPT-4模型的架构、训练数据集、参数、成本等重要信息进行了深度揭秘。(地址:https://www.semianalysis.com/p/gpt-4-architecture-infrastructure?nthPub=11)
文章指出,GPT-4的模型参数在1.8万亿左右、13万亿训练数据、一次训练成本6300万美元等。
SemiAnalysis曾曝光过谷歌的内部文件“我们、OpenAI都没有护城河”,其真实性得到了验证。所以,此次爆料的GPT-4大模型数据,不少人认为比较靠谱。
例如,此次爆料的GPT-4的参数在1.8万亿左右。前几天著名黑客George Hotz在接受采访时表示,GPT-4由8个混合模型组成每个模型参数为2200亿,数据上基本一致。

George Hotz接受采访,谈GPT-4的模型参数
SemiAnalysis认为,OpenAI一直不对外公布GPT-4的核心数据,并不是因为风险问题,而是GPT-4大模型是可以复制的。事实上,像谷歌、Meta、Anthropic、百度、字节跳动、腾讯等科技公司,都有实力开发出这样的产品。
「AIGC开放社区」根据SemiAnalysis的文章,对GPT-4大模型的核心数据进行了整理,以下内容仅供参考。
模型架构
GPT-4的模型参数大约是GPT-3 (公布参数为1750亿)的10 倍以上。SemiAnalysis认为,其在120 层网络中总共有1.8万亿参数。

OpenAI通过使用混合专家 (MoE) 模型能够将成本保持在合理水平。在GPT-4模型中使用了 16个专家模型,每个MLP专家大约有1110亿个参数。每个前向传递都会路由其中2个专家。
虽然OpenAI在文献中大量论述了用于选择将每个token路由到哪些专家的高级路由算法,但对于当前的 GPT-4 模型来说,OpenAI的算法相当简单。模型中大约有550亿个参数,被用做注意力机制的共享。
每次的前向传播推理(生成一个token)中,GPT-4只需要使用大约2800亿参数和560TFLOPs。相比之下,纯密集模型每次前向传播需要大约1.8 万亿个参数和约3700 TFLOP 的计算量。
关于混合专家模型:混合专家是一种机器学习模型,通过将多个子模型(称为“专家”)的预测结果进行组合,以获得更好的总体预测效果。
MoE模型的基本思想是,不同的子模型可能会在处理不同类型的输入数据时表现出优势。
例如,在处理图像数据时,某些模型可能擅长识别形状,而其他模型可能擅长识别颜色。通过将这些子模型的预测结果混合在一起,MoE模型可以在各种任务中实现更好的性能。
训练数据
OpenAI大约在13万亿token数据上训练了GPT-4。这些训练数据是重复计算之后的结果,多个 Epoch 中的 token 都计算在内。据悉,谷歌的大模型PaLM 2也使用了大约5万亿token的训练数据。

Epoch数量:针对基于文本的数据进行了 2 个 Epoch 的训练,而针对基于代码的数据进行了 4 个 Epoch 的训练。此外,还有来自 ScaleAI 和内部的数百万行的指令微调数据。
在预训练阶段,GPT-4使用了8k 的上下文长度,而32k的版本是基于预训练后的8K版本微调而来的。
并行策略
并行策略对于在A100GPU进行优化相当重要。为了在所有 A100 GPU上进行并行计算,OpenAI采用了8路张量并行,因为这是NVLink的极限。除此之外,据说OpenAI采用15路并行管线。

理论上,考虑到数据通信和计算时间,15个管线就有些多了。但是一旦加上了KV缓存和成本,如果OpenAI使用的GPU大部分是40GB的A100,那这样的构架在理论上就是有意义的。
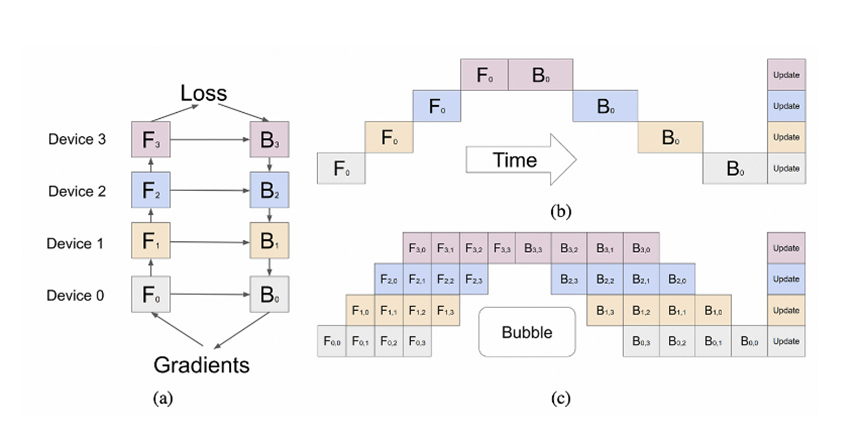
至于为什么不使用完整模型的 FSDP,可能是因为通信开销较高。虽然 OpenAI 在大多数节点之间具有高速网络,但可能并非在所有节点之间都具有高速网络。
训练成本
OpenAI训练GPT-4的FLOPS约为2.15e25,在大约25000个A100上训练了90到100天,利用率在32%到36%之间。故障数量过多也是极低利用率的原因,这会导致需要重新从之前的检查点开始训练。

如果OpenAI云计算的成本是差不多1美元/每A100小时的话,那么在这样的条件下,仅一次训练的成本大约是6300万美元。不包括所有的实验、失败的训练和其他成本,例如,数据收集、RLHF、人力成本等。
如果使用约8192个H100 GPU(每小时2 美元)进行预训练,时间降至55 天左右,成本为 2150 万美元。
SemiAnalysis认为,到今年年底,将有 9 家公司拥有更多H100。其中,Meta 将拥有超过 10万个H100,但其中很大一部分将分布在其数据中心用于推理。
专家模型的权衡
MoE是一种在推理过程中减少参数量的很好方法,但同时他会增加参数量。如果OpenAI真的想追求最佳性能,他们需要训练2倍的token数据才能达到。
采用相对比较少的专家模型的原因很多,OpenAI选择16个专家的原因之一在于,在执行许多任务上,更多的专家模型很难泛化,也更难实现收敛。

OpenAI 也做出了多种权衡。例如,在推理过程中处理 MoE 非常困难,因为并非模型的每个部分都在每个 token 生成时被利用。
这意味着在某些部分被使用时,其他部分可能处于闲置状态。在为用户提供服务时,这会严重影响资源利用率。研究人员已经证明使用 64 到 128 个专家比使用 16 个专家能够实现更好的损失,但这仅仅是研究的结果。
选择较少的专家模型有多个原因。OpenAI 选择 16 个专家模型的一大原因是:在许多任务中,更多的专家模型很难泛化,也可能更难收敛。
推理权衡
大型语言模型的推理存在3个主要权衡,这些权衡沿着批量大小(服务的并发用户数量)维度和所使用的芯片数量进行。
延迟:模型必须以合理的延迟做出响应。用户不想在等待其输出时,等待很长的时间。预填充(输入token)和解码(输出token)需要不同的时间来处理。
吞吐量:模型必须每秒输出一定数量的token。用户使用时需要每秒大约 30 个token。较低和较高的吞吐量,对于各种其他用例来说都是可以的。
利用率:运行模型的硬件必须达到高利用率,否则成本太高。虽然较高的延迟和较低的吞吐量,可用于将更多的用户请求分组在一起实现更高的利用率,但它们使其变得更加困难。

GPT-4引入专家混合 (MoE) 的模型架构引面临着一系列全新的困难。每个token生成前的传递都可以路由到不同的专家组。这会影响在较高批量大小下吞吐量、延迟和利用率轴实现的权衡。
OpenAI 在 128 个 GPU 的集群上运行推理。在多个数据中心和地区拥有多个这样的集群。推理是在8路张量并行和16路管道并行下完成的。每个包含 8 个 GPU 的节点只有约 1300亿 参数,或者在 FP16 下每个 GPU 小于 30GB,在 FP8/int8 下每个 GPU 小于 15GB。
包含不同专家的各个层不会跨不同节点进行解析,因为这会使网络流量变得不太规则,并且在每个token生成之间重新计算 KV 缓存的成本太高。未来,任何 MoE 模型扩展和条件路由的最大困难是,如何处理 KV 缓存周围的路由。
GPT-4推理成本
与拥有1750亿参数的Davinchi模型相比,GPT-4的成本是其3倍,尽管其前馈参数只增加了1.6倍。这主要是因为GPT-4需要更大的集群,并且实现的利用率更低。

在用128 个A100 GPU进行推理的情况下,GPT-4的8k序列长度每1000个标记的成本为0.0049美元,而在128个H100上推理GPT-4的8k序列长度每1000个标记的成本为0.0021美元。需要注意的是,这是假设有相当高的利用率,并保持较高批大小的情况下。如果 OpenAI 不这样做,他们的利用率会更低,估计成本会增加一倍以上。
多查询注意力
OpenAI和其他科技公司一样,也在使用MQA(Multi-Query Attention)。简单来说只需要一个注意力头,并且可以显著减少KV缓存的内存占用。
即便如此,32k长度的GPT-4肯定无法在40GB的A100上运行,而8k的最大批大小也有上限。
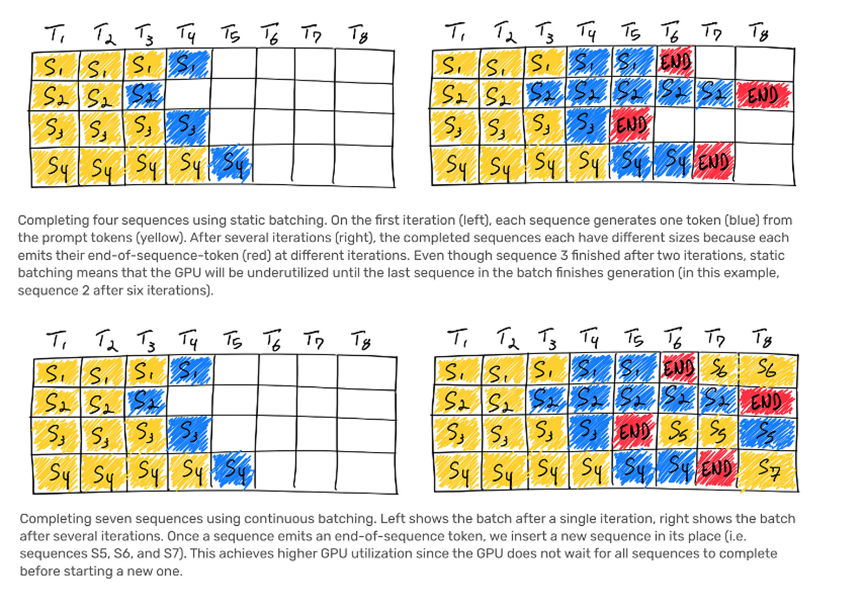
连续批处理
OpenAI实现了可变批大小和连续批处理。这样做是为了允许一定程度的最大延迟,并优化推理成本。
推测性解码
推测解码OpenAI在GPT-4的推理过程中使用了——推测解码(Speculative Decoding)。
推测解码的基本原理是使用一个更小、更快的草案模型提前解码多个token,然后将它们作为一个批输入到预测模型中。如果OpenAI使用推测解码,可能只在大约4个token的序列中使用。

此外,谷歌的Bard可能也使用了同样的技术,会等待整个序列生成后再将其发送给用户。
视觉多模态
这是一个独立于文本编码器的视觉编码器,二者之间存在交叉注意力,该架构与 Flamingo类似。这在GPT-4的1.8万亿个参数之上增加了更多参数。

GPT-4多模态能力是在文本预训练之后,又用大约2万亿token进⾏了微调。对于视觉模型,OpenAI 本来希望从零开始训练,但由于其尚未成熟,所以他们决定先从文本开始训练来降低风险。据悉,从GPT-5开始,将从头进行视觉训练并且能生成图像,甚至处理音频内容。
这种视觉能力的主要目的之一是,使自主智能体能够阅读网页并转录图像和视频中的内容。他们训练的一部分数据是联合数据(包括渲染的 LaTeX / 文本)、网页的截屏、YouTube 视频(采样帧),并使用 Whisper 对其进行运行以获取转录文本。
本文素材来源SemiAnalysis官网、网络等,如有侵权请联系删除
END




