专注AIGC领域的专业社区,关注OpenAI、百度文心一言等大语言模型(LLM)的发展和应用落地,关注LLM的基准评测和市场研究,欢迎关注!
Midjourney、Stable Difusion在商业变现和场景化落地方面获得了巨大成功,这让OpenAI看到了全新的商机,也是推出DALL·E 3的重要原因之一。
上周,OpenAI宣布在ChatGPT Plus和企业版用户中,全面开放文生图模型DALL·E 3,同时罕见地放出了研究论文。
DALL·E 3与前两代DALL·E、DALL·E 2相比,在语义理解、图片质量、图片修改、图片解读、长文本输入等方面实现了质的飞跃,尤其是与ChatGPT的相结合,成为OpenAI全新的王牌应用。
论文地址:https://cdn.openai.com/papers/dall-e-3.pdf
下面「AIGC开放社区」将根据DALL·E 3的论文为大家解读其主要技术原理,各个模块的功能。
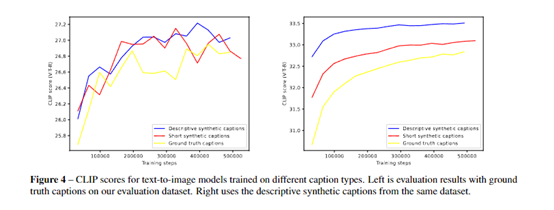
研究人员发现,文本生成图像模型在遵循详细的图片描述时经常存在各种难题,会忽略提示中的词语或混淆其含义,根本原因就是训练数据集中图像描述的质量较差。
为了验证这一假设,研究人员首先训练了一个生成描述性图像字幕的模型。该模型经过精心训练,可以为图像生成详细和准确的描述。
在使用这个模型为训练数据集重新生成描述后,研究人员比较了在原始描述和新生成描述上训练的多个文本生成图像模型。
结果表明,在新描述上训练的模型在遵循提示方面,明显优于原始描述模型。随后在大规模数据集上使用这种方法训练了——DALL-E 3。
从DALL-E 3的技术架构来看,主要分为图像描述生成和图像生成两大模块。
该模块使用了CLIP(Contrastive Language-Image Pretraining)图像编码器和GPT语言模型(GPT-4),可为每张图像生成细致的文字描述。
研究人员通过构建小规模主体描述数据集、大规模详细描述数据集以及设置生成规则等方法,使模块输出的图像描述信息量大幅提升,为后续生成图像提供强力支持。主要各个模块功能如下:
CLIP是一个训练好的图像文本匹配模型,可以将一张图像编码成一个固定长度的向量,包含了图像的语义信息。DALL-E 3利用CLIP的图像编码器,将训练图像编码为图像特征向量,作为条件文本生成的一部分输入。
DALL-E 3基于GPT架构建立语言模型,通过最大化随机抽取文本序列的联合概率,学习生成连贯的文字描述。
将上述两者结合,图像特征向量与之前的单词序列一同输入到GPT语言模型中,就可以实现对图像的条件文本生成。通过训练,该模块学会为每张图像生成细致Descriptive的描述。
尽管DALL-E 3的基础架构已经完成了,但直接训练的结果还不够理想,无法生成细节丰富的描述。所以,研究人员进行了以下技术优化:
-
构建小规模数据集,专门收集主体物详细描述,微调语言模型,倾向于描述图像主体。
-
构建大规模详细描述数据集,描述主体、背景、颜色、文本等各个方面,通过微调进一步提升描述质量。
-
设置生成描述的长度、样式等规则,防止语言模型偏离人类风格。
该模块先用VAE将高分辨率图像压缩为低维向量,降低学习难度。然后,使用T5 Transformer将文本编码为向量,并通过GroupNorm层将其注入diffusion模型,指导图像生成方向。
研究人员认为,额外加入的Diffusion模型显著增强了图片细节生成的效果。具体流程如下:
将高分辨率图像先通过VAE模型压缩为低维向量,以降低图像生成的难度。DALL-E 3采用8倍下采样,256px图像压缩为32×32大小的latent向量。
使用T5 Transformer等网络将文本提示编码为向量,以便注入到图像生成模型中。
这是图像生成的核心技术,将图像生成问题分解为多次对噪声向量的小规模扰动,逐步邻近目标图像。关键是设计恰当的前向过程和反向过程。
将编码好的文本向量,通过GroupNorm层注入到Latent Diffusion模型中,指导每轮迭代的图像生成方向。
研究人员发现,在压缩image latent空间上再训练一个Diffusion模型,可以进一步提升细节生成质量。这也是DALL-E 3比前两代生成的图片质量更好的原因之一。
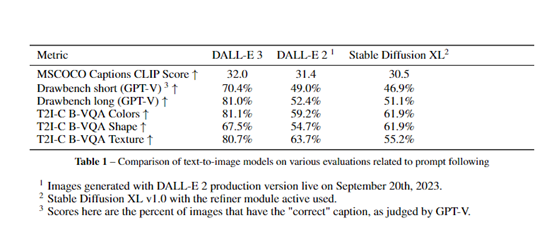
研究人员首先利用CLIP模型计算DALL-E 3生成图片与原描述文本的相似度,即CLIP得分。他们随机抽取了MSCOCO数据集中4096条图像描述作为提示文本,分别让DALL-E 2、DALL-E 3和Stable Diffusion XL生成对应图片,然后计算三者的平均CLIP得分。
结果显示,DALL-E 3的CLIP得分达到32.0,优于DALL-E 2的31.4和Stable Diffusion XL的30.5。
这表明DALL-E 3生成的图片与原始描述文本的契合度更高,文本指导图像生成的效果更好。
在Drawbench数据集上比较了各模型的表现。该数据集包含许多脆弱的文本提示,考验模型对提示的理解力。
研究人员使用GPT-V这个配备视觉能力的语言模型来自动判断生成图片的正确性。
在短文本提示的子测试中,DALL-E 3正确生成图像的比例达到70.4%,显著超过DALL-E 2的49%和Stable Diffusion XL的46.9%。
在长文本提示上,DALL-E 3的正确率也达到81%,继续领先其他模型。
通过T2I-CompBench中的相关子测试,考察模型对组合类提示的处理能力。在颜色绑定、形状绑定和质感绑定三项测试中,DALL-E 3的正确绑定比例均高居各模型之首,充分展现了其理解组合提示的强大能力。
研究人员还邀请了人工在遵循提示、风格连贯性等方面对生成样本进行判断。在170条提示的评估中,DALL-E 3明显优于Midjourney和Stable Diffusion XL。

本文素材来源OpenAI的DALL·E 3论文,如有侵权请联系删除
END