北大团队搞定ChatGPT都头痛的算法优化,普通笔电就能跑
添加书签

专注AIGC领域的专业社区,关注微软OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
衡宇 萧箫 发自 凹非寺
量子位 | 公众号 QbitAI
连ChatGPT看了都直摇头的算法优化,被北大团队给搞定了。
测试表明,新研究能解验证集中90%的题目,包括NOIP、Codeforce、Leetcode等比赛中的分治和动态规划题目——这些题目,很多大模型也难以解决。
而且自家的普通笔电就能跑!

毕竟算法优化这块,是大模型乃至整个AI的能力盲区。
哪怕是Nature刊发过的DeepMind AlphaTensor,给程序合成领域带来一些震撼不假,但实际作用对业内专业人士来说,“还是不够”。
所以,AI无法横扫到的这个领域,算法优化该咋提速提效?
北大一支团队,采取程序演算和程序枚举相结合的办法,做出了两套算法优化软件。
一套可以搞定分治、并行化、增量计算、线段树等算法的优化,另一套则支持动态规划算法的优化。
介绍动态规划算法的综合方法一篇(《Synthesizing Efficient Memoization Algorithms 》),已经被程序设计语言领域三大顶会之一的OOPSLA’23接收;另一篇关于分治类算法的论文也已经在arXiv(2202.12193)公开。
而且这两套软件需要的硬件门槛并不高,Intel Core i7-8700 3.2GHz 6核处理器就能跑,平均用时6.53s。
据悉,这两套软件未来都会开源,还会做成更易用的服务,放到网上。
有些神奇的事是,两篇论文共同的作者之一,北大副教授熊英飞,之前一度专研在AI领域,首次用CNN实现炉石传说的代码,就出自他之手。
带着好奇,我们和熊英飞本人聊了聊。

为什么AI设计算法还不行?
算法设计,需要给出满足规约的程序,并且在时间和空间复杂度上尽量优化。
大模型的进展有目共睹,因此,在“转向”之前,熊英飞和团队确实也想过用ChatGPT来搞算法设计。
(包括Copilot等代码补全和其他AI技术在内,他们将所有会写程序的AI都试了一遍,感觉ChatGPT最好用)
但即使是ChatGPT,在搞算法设计时也还是会出bug。
例如,将一些经典任务交给ChatGPT,它能很好地完成,如求解一个背包问题;但一旦对经典问题进行小改动,比如让物品重量和价值从其他属性组合得到,它输出的代码就会“一团乱”,完全没法用。
其关键原因,在于算法设计需要在程序语法语义、算法设计模式、算法复杂度分析等一系列专业知识的基础上,进行严密的逻辑推理。
现在,大模型主要在大量程序上做训练,很难仅靠训练就重新发现这些人类顶尖科学家研究了数十年的知识。
同时,虽然大模型具有少量分析能力,但要进行复杂和严谨的逻辑推理,在现在的神经网络架构下还存在困难。
这样写出来的代码,“即使跑得通,公司也不敢用”,因为修bug的成本可能比写bug还高(手动狗头)。

所以,有没有什么方法可以解决这个问题?
熊英飞表示,团队其实两种思路都在尝试,包括“用AI”和“不用AI”的。
一方面,他们训练了一个几亿参数的小模型,也在尝试使用AI来生成代码,同时也在思考AI和常规方法结合的来保证代码正确性的途径;
另一方面,团队也尝试将之前业界已有的两种方法结合起来,结果发现效果不仅比现在的AI方法更好,而且速度上也要更快。
所以,这种神奇的新思路究竟是什么?
先“找规律”,再“暴力穷举”
具体来说,熊英飞团队采用的新思路,结合了程序演算和程序枚举两种方法。
程序演算方法,简单来说就是“找规律”。
目前针对算法,已经有人总结出了许多不同的设计模式,有点像是一套代码设计经验的总结。
设计模式包含了许多算法优化相关的程序变换规则,类比到解方程中,就是左右加减移项、以及两边同乘同除等技巧。
算法优化也和解方程一样,虽然我们能学会不同的变换规则,但真正到了解决复杂问题的时候,还是得自己运用这套规则来对程序求解。

这种方法就和做数学题一样,需要用到一些“程序员的智慧”。但如果程序员想不到更好的解决方法怎么办呢?
因此,除了程序演算,此前还有一种思路是程序枚举,顾名思义就是“暴力穷举”。
这种方法就是让电脑去试所有可能的程序,经过验证后,总有一个程序是对的。例如给变量x和y,计算机就会尝试x+y,x-y……
但这种方法同样存在一个问题,就是虽然计算机很快,但世界上所有的程序太多了,而且基本上随着程序长度增加呈指数型增长。
因此,直接暴力穷举,对于计算机来说同样是不可能的。
为此,熊英飞团队结合这两种思路,设计了一种新的算法优化方法。
简单来说,就是先基于程序演算的思路,将问题缩小到只需要用程序去填写几个关键程序的情况,就像给“完形填空”挖空一样。
然后,用穷举法列举需要“填空”的程序,最终验证得到结果。
当然,这里面也用到了一些近似的技术,因为理论上,形式化规约无法完全和需要“填空”的部分对应起来,要填空的地方肯定也和其他地方有条件关系。
因此针对这种问题,团队也设计了一些技巧,确保在一定概率下这种方式不会出错。
相比AI而言,这种思路设计出来的算法优化软件,不仅正确率更高,解题过程也要更快。
目前,团队设计出了两套算法优化软件AutoLifter和SynMem。
其中AutoLifter支持分治、并行化、增量计算、单通道、流算法、线段树等算法的优化,SynMem则支持动态规划算法的优化。
所以,这两套算法优化软件的效果究竟如何?
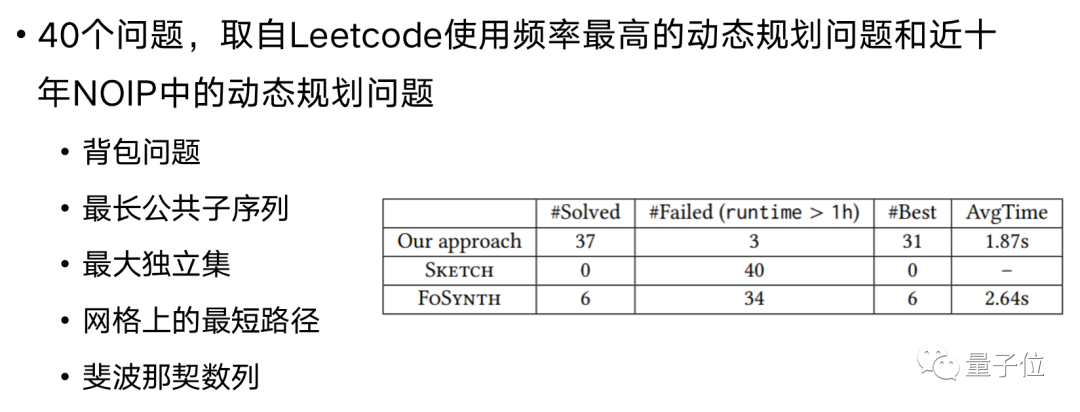
团队从Codeforces、NOIP全国青少年信息学奥林匹克联赛、Leetcode上收集了所支持算法对应的题目,对两套方法进行了测试
其中,在分治类的96个算法问题中,AutoLifter解出来了82题,相比之下另两种此前最好的程序合成方法,只解出来不到一半。

硬件要求也不高,只需要Intel Core i7-8700 3.2GHz 6核处理器就能跑,平均用时在6.53秒左右。
在40道动态规划题目上,团队解出来了37道,而且平均用时仅仅1.87秒 (相比之下另外两种方法几乎没有解出来多少):
这两套软件,团队在未来都会开源,也会做成更方便使用的服务放到网上。
熊英飞表示,最终的目标是希望做出一套软件,能自动检测到代码中需要优化的算法,然后软件自动将它们优化起来。
以App为例,即使啥都不做,用上这套算法后,对应的APP运行速度也能大幅增加。
当然,达成这一目标,可能还需要一段时间。
“发Nature耽误拿奖学金了”
AutoLifter这项工作背后的论文,是熊英飞团队3年前就开始的算法合成项目,完成的第一篇论文。
熊英飞给出的原因是之前的方法堪称“理论大合集”,不仅有程序合成,还加上了程序演算、范畴论、概率论、随机算法……总之,整篇论文充满了数学符号。
“这样一来,要找到合适的审稿人比较难。”熊英飞表示,2年间删删改改,现在论文已经是一个“不依赖于特定领域的符号,基本大家都能读懂的样子了”。
交流期间,量子位问了句题外话,AlphaTensor能发Nature,咱们的论文2年没被顶会接收,没考虑过投投Nature?
熊老师开玩笑地回应道:
我也劝我的博士生,不要跟程序设计顶会较劲,发篇Nature影响多大啊!试着投一下也不会掉块肉。
你知道他们怎么说?“不行,我要赶紧(在专业领域)发出来,不然明年奖学金没了!”
玩笑归玩笑,言归正传,介绍一下AutoLifter和SynMem两项工作的论文一作,两位都是算法竞赛圈的知名选手。
吉如一,AutoLifter工作论文一作。
北京大学编程语言实验室(PLL)博四在读,研究方向是程序合成,导师为胡振江和熊英飞。
2016年,吉如一以全国青少年信息学奥林匹克竞赛金牌获得者保送北大信息科学与技术学院,后成为北大第一届图灵班的一员。
曾担任ACM大赛北大队队长,第二次参赛时带队获得金牌和全球第三、亚洲第一的成绩。同时也是北京大学学生算法协会的创始人和第一任主席,人送外号“吉老师”。

孙奕灿,SynMem一作。
北京大学编程语言实验室(PLL)博三在读,指导教师为熊英飞。
他同样是全国青少年信息学奥林匹克竞赛金牌保送北京大学。
他的研究方向为程序合成、决策过程和概率程序验证,也做过一些关于参数化复杂度制度下的不可近似性的工作。
本科时,他就读于北京大学EECS学院图灵班。他曾以共同一作的身份在编程语言的顶级会议PLDI上发表论文,并且有其它工作发表在编程语言顶级会议OOPSLA和人工智能顶级会议AAAI上。

两篇论文的共同作者熊英飞,是上述二人的博士指导老师。
他的身份是北大信息科学技术学院软件工程研究所长聘副教授、研究员,分别在电子科技大学、北京大学、日本东京大学获得本硕博学位。
除了本文提到的程序合成,熊英飞的主要研究方向之一就还有缺陷修复领域,这也是他和所在组长期以来做的一项工作。
缺陷修复,俗称修bug,他做的工作还是自动修bug。
具体而言就是先读程序,分析出程序有哪些地方需要改,然后想出一个新的程序的写法。
熊英飞和团队提出的理论、方法和技术中,基于差别的修复模型已经成为演化缺陷领域广泛使用的模型之一,而基于统计的缺陷修复技术将程序缺陷修复的准确率提升约40%。
采用他们工作的公司,包括华为、Linux内核配置项目等。

之所以能达到这样的效果,熊英飞介绍道,是因为团队是最早把概率引导传统程序合成中的研究队伍之一。
这项发表在2017年的工作,通过统计引导程序合成,把缺陷修复正确率最高水平从40%拉到了70%。
有意思的是,此后许多研究机构都开始从概率统计和传统机器学习下手研究程序合成,但那时的熊英飞团队,却转而琢磨如何利用深度学习做程序合成。
2018年,他们发表一篇论文,提出基于语法的结构化CNN代码生成器,用《炉石传说》基准数据集进行实验。
结果表明,准确性明显优于以往最先进的方法5个百分点。

这篇论文最后被AAAI 2019收录,论文中表示,他们是第一个成功将CNN解码器用于代码生成的团队。
2019年,团队又用Transformer替换了CNN解码器,准确性再次提升约5个百分点。熊英飞笑道,一不小心做了最早应用Transformer生成代码的工作,“见证了历史”。
等到了2021年,团队再把上面的工作结合了基于差别的修复模型,做了一个缺陷修复工作。“那次就是深度学习修bug能力首次超过了传统技术。”熊英飞说。
不过略戏剧的是,等学界多数团队开始用深度学习来做程序合成、缺陷修复时,熊英飞团队又开始专研传统方法去了——结果就是,本文提到的两套算法优化软件诞生了。
听起来,他们团队在研究程序合成这条路上,颇有种“不管黑猫白猫”的精神。
还有一种大家一起摸鱼的传统美德:
其实算法优化软件暑期8月就该上线的,不过大伙儿都在摸鱼哈哈。
Fine,现在已经是10月了,不知道团队的 摸够了没有哇?doge
摸够了没有哇?doge
本文来源量子位,如有侵权请联系删除
END




