一次输入40万汉字,可免费商用!李开复的开源大模型「Yi」
添加书签

专注AIGC领域的专业社区,关注微软OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
11月6日,李开复亲自领导的零一万物在官网正式开源了,两款预训练大模型 Yi-34B和6B。
在Hugging Face 英文开源社区平台和C-Eval 中文评测显示,Yi-34B取得了多项 SOTA 国际最佳性能指标认可,成为全球开源大模型“双料冠军”,也是迄今为止唯一成功登顶Hugging Face 全球开源模型排行榜的国产模型。
Yi-34B的技术亮点包括支持200K 超长上下文窗口(context window)版本,可以处理约40万汉字超长文本输入,轻松理解一本小说和处理超过1000页的PDF文档,这对于法律、金融、营销等需要处理超长文本的行业来说帮助巨大。
此外,Yi系列模型完全开放供学术研究和免费商业使用,帮助开发者快速构建自己的“ChatGPT”助手,可以联系零一万物进行申请。(联系方式:yi@01.ai)
Github地址:https://github.com/01-ai/Yi
huggingface地址:https://huggingface.co/01-ai/Yi-34B
ModelScope地址:https://www.modelscope.cn/models/01ai/Yi-34B/summary
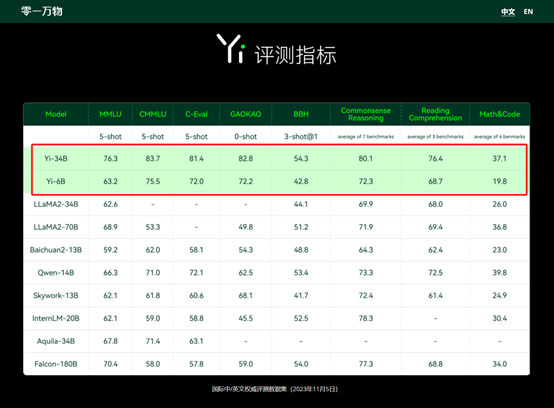
根据零一万物的介绍,在参数和性能方面,Yi-34B的参数不高却分别击败了LLaMA2-70B、Falcon-180B等知名大尺寸开源模型。
在多个知名综合能力评测集上,Yi-34B 在各项测试任务中也全部胜出取得了领跑者的成绩。作为国产优质大模型,Yi-34B更“懂”中文,在C-Eval中文权威榜单排行榜上超越了全球所有开源模型。

与OpenAI的GPT-4相比,在CMMLU、E-Eval、Gaokao 三个重要的中文评测上,Yi-34B 也具有绝对优势;在BooIQ、OBQA两个问答指标上,和GPT-4水平相当。
此外,在大模型最关键评测指标MMLU、BBH等反映模型综合能力的评测集上,Yi-34B在通用能力、知识推理、阅读理解等多项指标评比中全面超越,与Hugging Face评测高度一致,完美凸显了Yi-34B优异的中文阅读理解能力,同时可以更好地满足国内客户需求。
不过零一万物表示,Yi系列模型在GSM8k、MBPP的数学和代码测评中表现还不及GPT模型。这是因为研发团队希望在预训练阶段先尽可能保留模型的通用能力,所以训练数据中没有加入过多数学和代码数据。

所以,接下来零一万物将基于Yi 基座模型,快节奏开源发布一系列的量化版本、对话模型、数学模型、代码模型和多模态模型等,邀请开发者积极投入,共同促进语言模型开源社区的繁荣发展,培育新型“AI-first”创新生态体系。
零一万物创始人兼CEO李开复表示,零一万物从招的第一位员工,写出第一行代码,设计的第一个模型开始,就一直抱着成为‘World’s No.1’的初衷和决心。
带着进军全球第一梯队的目标,我们组成了一支有潜力对标 OpenAI、Google等一线大厂的技术团队。经历了近半年的技术迭代,我们顺利交出了一张极具全球竞争力的大模型成绩单。

关于零一万物
零一万物是中国创新工场的AI2.0孵化项目,由李开复博士亲自领导,致力于打造中国领先的大模型技术团队
零一万物总部位于北京,拥有数十名专业人士,擅长大模型技术、人工智能算法、自然语言处理等领域。零一万物的核心初创团队来自全球一线科技大厂,包括前阿里巴巴副总裁、前百度副总裁等。
零一万物拥有自主研发大模型的能力和经验,已在百亿参数级别上取得了突破。零一万物的技术愿景是不仅仅做通用大模型,还要做能够处理图片、视频、3D等多种数据类型的多模态模型。
李开复认为,自研大模型是实现AI2.0的必要条件,不能完全依赖于开源模型和小模型,要建立自己的技术优势和生态壁垒。
因此,零一万物将致力于打造一个开放、共享、协作的大模型平台,与全球的研究者、开发者、创业者共同探索和创造AI2.0的未来。
本文素材来源xxxx,如有侵权请联系删除
END




