专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
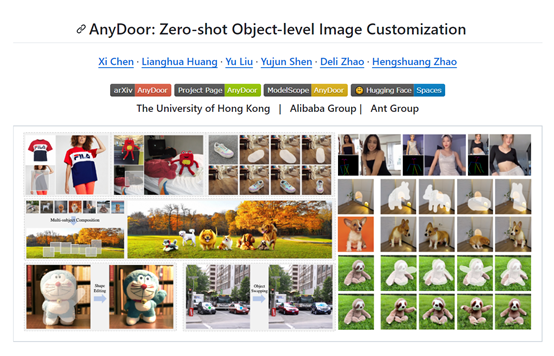
香港大学、阿里集团、蚂蚁集团联合开源了基于扩散模型的,图像生成、控制模型——AnyDoor。
AnyDoor的主要功能是“图像传送”,就是将一张图像的内容融合到另外一张图像中,例如,将女生的蓝色短袖换成,其他样式的红色衣服。
所以,也可以理解成“一键PS合成”或者PS中的内容感知移动工具。
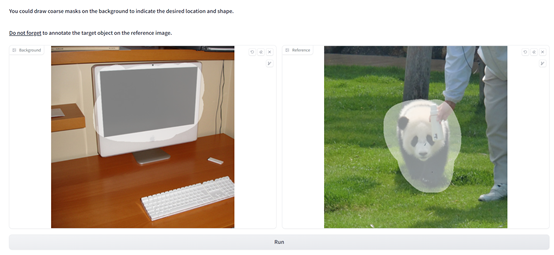
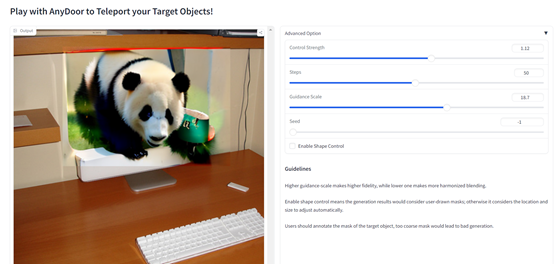
根据「AIGC开放社区」使用其在线demo的体验,操作方法非常简单,上传图片然后标注涂抹区域即可。
整个功能强大且可视化,用户可以控制强度、种子、指导量表等参数,使得融合的图像更加细腻、逼真。
目前,AnyDoor在Github达到3000颗星,非常受欢迎。
开源地址:https://github.com/ali-vilab/AnyDoor
论文地址:https://arxiv.org/abs/2307.09481
Demo地址:https://huggingface.co/spaces/xichenhku/AnyDoor-online
AnyDoor的核心技术思路是同时表示身份和细节。表示身份,通过自监督模块提取语义一致的 ID 特征;
表示细节,则利用高频区域捕捉表面纹理,既能保持纹理细节,又能实现灵活的局部变化(光照、方向、姿势等),使得对象能够与不同的环境进行良好的融合。
与传统方法不同,AnyDoor模型只需进行一次训练,便能够在推理阶段广泛应用于不同的对象、场景组合,而无需为每个对象调整参数。
传统方法是使用CLIP图像编码器来嵌入目标对象。但CLIP是基于粗略描述的文本图像对训练的,只能嵌入语义级别的信息,而无法给出保留对象身份的可辨认表示。
为了解决这一难题,研究人员进行了两大创新:1)移除背景,在将目标图像馈送到ID提取器之前,使用分割器移除背景并将对象与图像中心对齐。这种操作被证明有助于提取更整洁和更可辨认的特征。
2)自监督表示,在大规模数据集上预训练,自监督模型具备实例检索能力,可以将对象投影到一个数据增强不变的特征空间中。
研究人员使用了目前最佳的自监督模型之一DINO-V2作为ID提取器的主干,将图像编码为一个全局表示和一系列区域表示,通过连接这两类表示来保留更多信息。
最后,通过一个线性层将这些表示与预训练的文本到图像UNet的嵌入空间对齐,投影后的表示作为ID标记。
当ID标记失去了空间分辨率,会很难充分表示目标对象的细微细节。因此,需要额外的指导以在互补的方式生成细节。为了使融合的图像更加逼真、丝滑,研究人员使用了两种辅助方法来实现。
拼贴表示:将“去背景的目标对象”拼贴在给定场景的指定位置,以改善生成图像的保真度。
但生成的内容与给定目标过于相似,缺乏多样性,所以,研究人员又设置了一个信息瓶颈以防止拼贴给出太多外观约束。
高频图:提取目标对象的高频图,这可以保持细微细节,同时允许姿态、照明、方向等各种局部变体。
研究人员使用Sobel作为滤波器,首先提取图像的高频区域,然后使用Hadamard乘积提取RGB颜色,同时添加了腐蚀掩模来过滤目标对象外轮廓附近的信息。
得到高频图后,根据给定的位置将其拼接到场景图像上,再将拼接结果传递给细节提取器,二者之间进行深度融合实现更好的效果。
研究人员表示,AnyDoor模型主要用于一键换脸/换衣、虚拟试穿、在线PS等业务场景。可以让很多不懂技术的电商卖家,也能实现专业PS的功能。
本文素材来源AnyDoor论文,如有侵权请联系删除
END

本篇文章来源于微信公众号: AIGC开放社区