微软等开源评估ChatGPT、Phi、Llma等,统一测试平台
添加书签
专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
微软亚洲研究院、中国科学院自动化研究所、中国科学技术大学和卡内基梅隆大学联合开源了,用于评估、分析大语言模型的统一测试平台——PromptBench。
Prompt Bench支持目前主流的开源、闭源大语言模型,例如,ChatGPT、GPT-4、Phi、Llma1/2、Gemini、Baichuan、Yi 等。
PromptBench内置了丰富的评估工具,包括提示构建、提示工程、数据集和模型、对抗性提示攻击、性能评测等。用户可以根据实际开发情况灵活配置,非常简单高效。
开源地址:https://github.com/microsoft/promptbench
论文地址:https://arxiv.org/abs/2312.07910
对大型语言模型进行评估、分析是理解其真实输出、减少潜在风险的重要开发环节。
研究人员表示,目前多数大型语言模型对文本提示非常敏感,容易受到对抗性提示攻击,同时易受到数据污染的影响,这给安全和隐私带来了巨大挑战。
虽然有很多类似lm-eval-harness的评估框架,但其评估模块和功能较少,无法满足飞速发展的大语言模型领域。
所以,微软等研究人员希望开发一个统一的评估平台,帮助开发者提升测试效率,同时减少大模型的非法内容输出。
PromptBench简单介绍
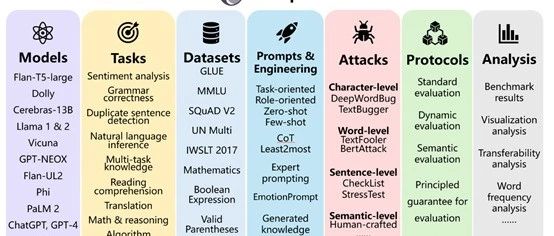
PromptBench可以从多个维度对大语言模型进行评估,涵盖多个任务、评估协议、对抗性提示攻击和提示工程技术、数据集等。
评估协议是PromptBench的核心模块之一,主要定义了评估大语言模型性能的方法和流程。

PromptBench支持多种评估协议,包括静态评估和动态评估。静态评估是,通过提供预定义的提示来测试大语言模型的性能;
动态评估,则允许在交互过程中动态生成和修改提示。这种灵活性使研究人员能够更全面地评估大语言模型的能力和鲁棒性。
对抗性提示攻击,是评估大语言模型安全性的重要方法之一。PromptBench提供了多种对抗性提示攻击的测试方法,包括,字符级修改、词级替换、句级添加和语义级改写等攻击。有效模拟了提示使用中可能遇到的各类偏差情况,检验了模型的攻击鲁棒性。
数据集是评估大语言模型性能的关键部分。PromptBench提供了20多个公开的评估数据集,涵盖了文本分类、语法纠错、句子相似度判定、自然语言推理、多任务问答、阅读理解、翻译、数学推理、逻辑推理等,可以充分测试大语言模型在不同场景下的表现和能力。
支持哪些大语言模型
PromptBench支持目前市面上主流的开源、闭源大语言模型,包括Flan-T5-large、Dolly系列、Cerebras-13B 、Llama系列、Vicuna 、GPT-NEOX;
Flan-UL2、Phi 、PaLM 2、ChatGPT、GPT-4、Gemini、Mistral、Mixtral、Baichuan、Yi等。
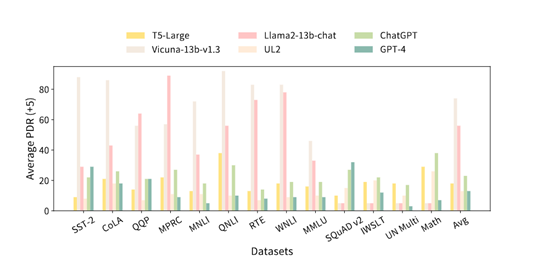
研究人员表示,未来会持续更新对大语言模型的支持,将打造成一个涵盖模型最多、评估功能最全的统一测试平台。
本文素材来源PromptBench论文,如有侵权请联系删除
END

本篇文章来源于微信公众号: AIGC开放社区



