让大模型忘掉隐私数据,卡内基开源TOFU
添加书签
专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
目前,多数大语言模型都是从网络上收集的大量数据进行预训练、微调。使得这些模型面临泄露用户隐私、数据安全等多种问题。
尽管开发者提出了各种“遗忘”方法,能使大模型“忘记”训练数据中的某些隐私、敏感的数据。但很多方法非常有限,同时缺少有效的数据评估集。
因此,卡内基梅隆大学的研究人员提出了TOFU框架,包含遗忘、数据集、评估等多个模块,以帮助开发者提升大模型的安全性。
开源地址:https://github.com/locuslab/tofu
论文地址:https://arxiv.org/abs/2401.06121

TOFU数据集
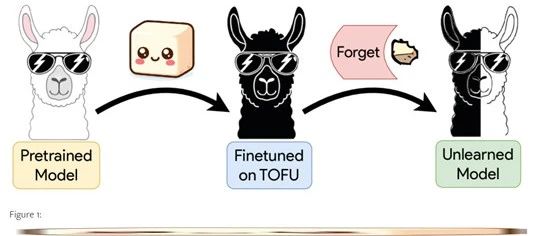
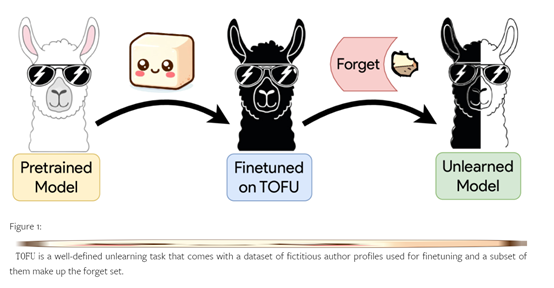
TOFU数据集旨在帮助我们更深入地理解大模型的遗忘过程。通过TOFU数据集,开发人员可以精确控制模型对合成作者资料的接触程度,以模拟一个在训练集中只出现一次的私人个体,帮助我们评估遗忘的效果。
该数据集由200个多样化的合成作者资料组成,每个资料包含20个问题-答案对。其中的子集称为”遗忘集”,主要用于进行遗忘的目标数据。
为了评估遗忘方法的有效性,TOFU数据集提供了全新的评估方案,涵盖了遗忘质量和模型效用两个方面的比较。对于模型效用,研究人员不仅计算了几个性能指标,还创建了新的评估数据集,这些数据集构成了一个相关性梯度,有助于衡量遗忘过程的影响,将这些数字综合为一个模型效用指标。
为了评估遗忘质量,研究人员提出了一种新的度量方法,比较了生成的真实答案和错误答案在遗忘集上的概率。然后使用统计测试方法将遗忘模型与从未在敏感数据上进行训练的标准模型进行比较。

此外,研究人员还评估了四种基线方法在不同遗忘严重程度上的表现,比较了模型效用和遗忘质量。
这些基线方法考虑了不同数量的任务信息和计算量,例如,使用神经网络模型进行输出匹配,需要更多的数据和前向传递。
TOFU遗忘模块
遗忘模块是TOFU的另外一个核心功能,可以帮助开发者从大语言模型中移除敏感数据,使其在行为上表现得好像从未学习过这些遗忘数据一样。
遗忘模块需要根据遗忘集的数据对模型进行调整,以实现遗忘效果。主要包含参数调整和样本选择两种方法。
参数调整:该方法主要通过修改模型的参数,来实现遗忘效果。遗忘模块会根据遗忘数据集的样本重新训练模型,但在训练过程中会有所改变。
常见的方法是,将遗忘集的样本标记为”遗忘”或”无效”,并与原始训练数据一起使用。在训练过程中,模型会尽量调整参数以减少对遗忘集的依赖性,从而达到遗忘敏感信息的效果。
样本选择方法:该方法通过选择性地使用遗忘数据集的样本,来实现遗忘效果。遗忘模块会根据一定的准则从遗忘数据集中选择一部分样本,并仅使用这部分样本进行模型的训练。

这些样本通常被认为是与敏感信息最相关的样本。通过仅使用这些样本进行训练,模型可以逐渐遗忘与这些样本相关的敏感信息或相关性进行筛选,以便更有针对性地移除敏感数据。
本文素材来源TOFU论文,如有侵权请联系删除
END

本篇文章来源于微信公众号: AIGC开放社区



