支持534种语言,开源大语言模型MaLA-500
添加书签
专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
无论是开源的LLaMA 2还是闭源的GPT系列模型,功能虽然很强大,但对语言的支持和扩展比较差,例如,二者都是以英语为主的大模型。
为了提升大模型语言的多元化,慕尼黑大学、赫尔辛基大学等研究人员联合开源了,目前支持语言最多的大模型之一MaLA-500。
MaLA-500以LLaMA 2为基础模型,再用多语言数据库Glot500-c进行语言扩展训练,支持语言达到了惊人的534种。
开源地址:https://huggingface.co/MaLA-LM/mala-500
论文地址:https://arxiv.org/abs/2401.13303

训练数据
研究人员选用了开源数据集Glot500-c对MaLA-500进行了语言扩展训练。该数据集包含了534种语言,涵盖47种不同种族语言,数据量高达2万亿tokens。
研究人员表示,选择Glot500-c数据集的原因在于,可以大幅扩展现有语言模型的语言覆盖范围,并包含极其丰富的语言家族,这对于模型学习语言内在的语法和语义规律帮助巨大。
此外,虽然一些高资源语言的比例相对较低,但Glot500-c的整体数据量对训练大规模语言模型而言足够用。在后续的预处理中,又对语料数据集进行了加权随机采样,以增加低资源语言在训练数据中的比例,让模型更加聚焦特定语言。
基础模型LLaMA 2
MaLA-500选择了目前最知名的开源大语言模型之一LLaMA 2-7B作为基础模型,并进行了两大技术点创新。
1)增强词汇表,研究人员通过Glot500-c数据集,训练了一个多语言分词器,将LLaMA 2的原英文词汇表扩展到了260万,大幅增强了模型对非英语和低资源语言的适配能力。
2)模型增强,使用了LoRA技术在LLaMA 2的基础上进行低秩适配。只训练适配矩阵而冻结基础模型权重,可以高效地实现模型在新语言上的持续学习能力,同时保留模型原有的知识。
训练流程
训练方面,研究人员用了24张N卡A100 GPU进行训练,并使用了包括Transformers、PEFT和DeepSpeed三个主流深度学习框架。
其中,DeepSpeed提供了分布式训练的支持,可以实现模型并行;PEFT实现了高效的模型微调;Transformers提供了模型功能的实现,例如,文本生成、提示词理解等。
为了提升训练的高效性,MaLA-500还使用了各种显存和计算优化算法,如ZeRO冗余优化器,可最大化利用GPU算力资源;以及混合精度训练的bfloat16数格式加速训练流程。
此外,研究人员还对模型参数进行了大量优化,使用了学习率为2e-4的常规SGD训练,并使用了0.01的L2权重衰减以防止模型过大,出现过拟合、内容输出不稳定等情况。
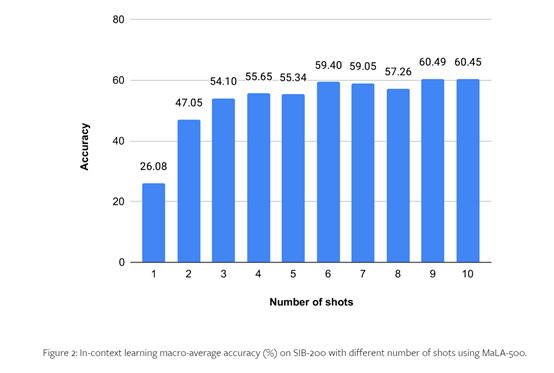
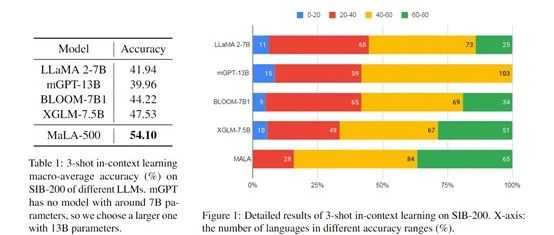
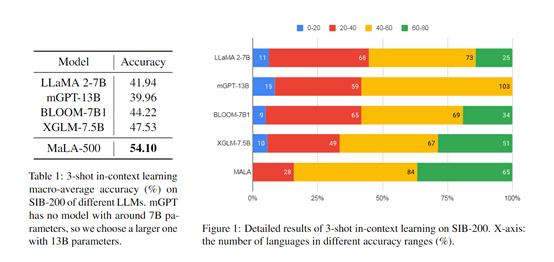
为了测试MaLA-500的性能,研究人员在SIB-200等数据集上进行了综合实验。
结果显示,相比原始LLaMA 2模型,MaLA-500在主题分类等评测任务上的准确率提高了12.16%,这说明MaLA-500的多语言优于,现有的众多开源大语言模型。
本文素材来源MaLA-500论文,如有侵权请联系删除
END


本篇文章来源于微信公众号: AIGC开放社区



