开放数据、训练代码等所有内容,AI2开源大模型OLMo
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
目前,开源的大模型有很多,但是完全开放的内容却很少。例如,开源大模型Mistral 8x7B只提供了模型权重和简短的报告;Mosaic提供了许多预训练细节,但没有提供数据本身等。
很多开源大模型都是伪开源,他们会把一些核心内容封闭起来。因此,全球著名AI研究机构AI2 (艾伦人工智能研究所)完全开源了OLMo的型权重、训练代码、消融实验、训练日志、中间检查点、训练指标、推理代码等所有核心模块。
Github地址:https://github.com/allenai/OLMo
论文地址:https://allenai.org/olmo/dolma-paper.pdf

OLMo框架简单介绍
OLMo一共包含OLMo-1B、OLMo-7B和OLMo-65B,每个模型都至少使用200T的训练数据,预训练数据集Dolma和评估框架,并公开了模型的所有核心模块。
训练模块:OLMo提供了完整的训练模块,包括训练代码、训练日志和训练指标。开发人员可以使用这些模块来训练自己的语言模型,并根据自己的需求进行调整和指令优化。
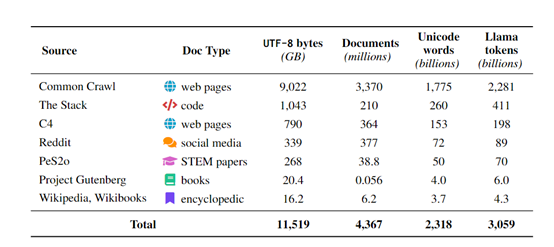
数据流程:OLMo通过预处理和清洗大规模的文本数据,将其转换为适合语言模型训练的格式,包括分词、词向量化和数据集划分等关键流程。
模型构建:选择适当的模型架构和超参数设置,并构建出语言模型的初始状态。
模型训练:使用大规模的训练数据集对语言模型进行预训练,使用梯度下降算法来最小化模型的损失函数,并更新模型的权重和偏置。
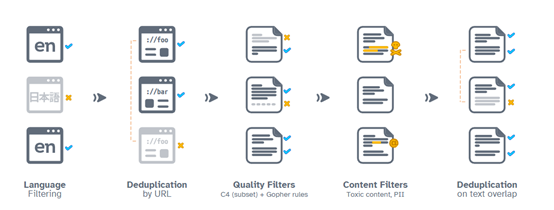
迭代优化:通过多次迭代训练,不断优化模型的性能和泛化能力。包括调整学习率、使用正则化技术和增加训练数据的多样性等方法。
数据集和分析模块
数据收集:从各种来源(如互联网、文本语料库、社交媒体等)收集大规模的文本数据作为训练数据。这可以通过爬虫程序、API接口或人工标注来实现。
数据预处理:对收集到的数据进行预处理,包括词汇化、分词、去除噪声和标点符号等。这有助于提高语言模型的训练效果和泛化能力。
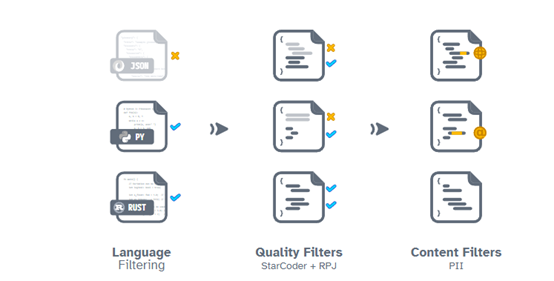
数据分析:通过统计和可视化方法,对训练数据进行深入分析。这可以帮助研究人员了解数据的分布、词频分布和语义关系等,以更好地理解语言模型的训练数据。
评估、模型权重和推断模块
任务评估:使用已有的任务数据集(如文本分类、命名实体识别、情感分析等)对训练好的语言模型进行评估。这可以帮助研究人员了解模型在实际应用中的性能表现。
困惑度评估:通过计算语言模型在给定文本序列上的困惑度来评估模型的语言建模能力。困惑度是一个衡量模型预测能力的指标,数值越低表示模型越好地捕捉了语言的概率分布。
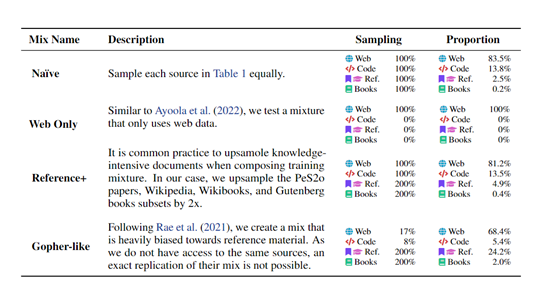
效果可视化:通过可视化工具和方法,将语言模型的输出结果可视化,以帮助研究人员更好地理解模型的预测行为和输出的置信度。
模型加载:将训练好的语言模型的权重加载到内存中,以便进行推断和生成。
推理和生成:使用加载的模型权重对给定的文本序列进行推理和生成,可以是生成下一个单词、填充缺失的单词或生成完整的文本段落等。
总体来说,A12开源OLMo从0到1展示了开发一个大语言模型的所有流程,希望可帮助科研人员、企业、个人开发者更好地理解大模型的原理并更好地训练自己模型。
本文素材来源OLMo,如有侵权请联系删除
END


本篇文章来源于微信公众号: AIGC开放社区



