微软开源SliceGPT:极限压缩大模型权重矩阵,并保持性能不变
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
ChatGPT、Midjourney、Gen-2等不同大模型的影响力越来越大。但无论部署开源还是闭源这类模型并不容易,需要耗费大量AI算力、内存等硬件资源。
为了解决这些难题,微软和苏黎世联邦理工学院的研究人员开源了SliceGPT,通过对大模型的每个权重矩阵进行压缩、切片,变为更小的紧密矩阵,从而节省大量部署资源。
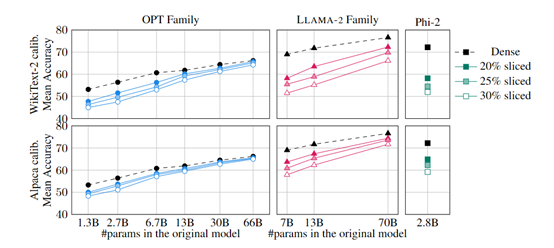
实验数据显示,SliceGPT可以保持LLAMA-2 70B、OPT 66B和Phi-2等模型的零样本任务性能分别为99%、99%和90%的情况下,将模型的参数体量压缩了25%左右。
此外,SliceGPT可以直接在消费级显卡上运行,例如,N卡的4090、4080而不需要任何额外的代码优化。
开源地址:https://github.com/microsoft/TransformerCompression
论文地址:https://arxiv.org/abs/2401.15024

目前,压缩大模型的主流方法主要有蒸馏、张量分解(包括低秩分解)、修剪和量化4种模式。但这些模式皆需要大量AI算力来支持,对于中小企业和普通开发者并不友好。
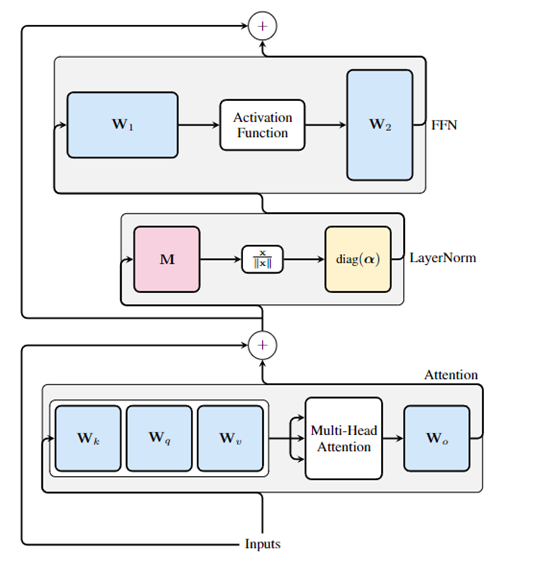
研究人员发现,在Transformer架构中,可以对权重矩阵应用正交矩阵变换,而不用改变模型的预测能力,因此,通过这一发现开发了SliceGPT创新压缩技术。
SliceGPT主要利用主成分分析,针对每个Transformer块计算一个正交矩阵,并将信号投影到主成分上。然后,通过删除某些行和列,以减小权重矩阵的大小,从而压缩模型体量。
计算不变性
SliceGPT的核心技术是利用Transformer架构中的“计算不变性”来简化和压缩模型。
计算不变性是指对网络的每个权重矩阵应用正交矩阵变换,而不改变模型的预测结果。
为了实现计算不变性,研究人员引入了一个新的变换矩阵Q,将每个权重矩阵W变换为Q⊤W。这个变换保持了预测结果不变,但允许切片操作只对模型产生较小的影响。
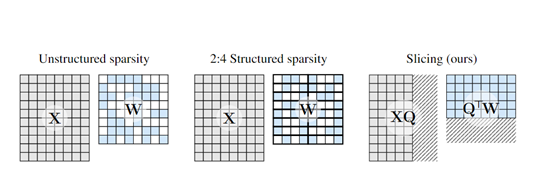
接下来,对变换后的权重矩阵进行细分化切片,通过删除权重矩阵的行或列来减小模型的尺寸。
在SliceGPT中,将稀疏性集中在权重矩阵的底部行,并删除相应的列。通过这种方式,权重矩阵的尺寸变小,从而减小了模型的参数量和计算需求。
切片操作后,大模型变得更加稀疏,可以跳过一部分矩阵乘法中的浮点运算,从而提高前向传播的速度。
此外,由于模型尺寸减小,传递给神经网络各个模块的信号也变得更小,从而减小了嵌入参数维度。
SliceGPT技术特点
简单高效:SliceGPT的计算不变性技术和切片操作都很简单,可以在几个小时内使用单个GPU完成模型压缩,而无需昂贵、费时的细调过程。普遍模型的压缩率在30%左右。
保持性能:即使在没有恢复微调的情况下,SliceGPT仍能保持高质量的生成任务的性能,可以在减小模型尺寸的同时保持模型的准确预测能力。
吞吐量提升:一次性片切即可,无需重复训练调参。切片后的矩阵仍然稠密,计算速度更快,批处理大小也可以加大,所以,总体吞吐量提升明显。
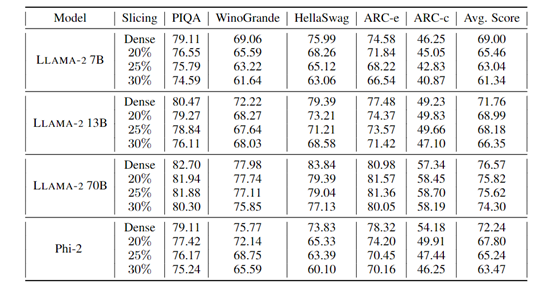
无需额外代码优化:与其他压缩方法不同,SliceGPT的切片技术不需要进行额外的代码优化。
在实验中,研究人员使用了普通的消费级GPU进行推理,结果显示,切片后的模型在运行速度上比稠密模型更快,而无需进行额外的代码优化。
本文素材来源SliceGPT论文,如有侵权请联系删除
END


本篇文章来源于微信公众号: AIGC开放社区



