追赶OpenAI的Sora:Meta开源V-JEPA,让AI学会认识世界!
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
就在Sora疯狂刷屏那天,还有两款重磅产品发布:一个是谷歌的Gemini 1.5,首个支持100万tokens上下文的大模型;另外一个便是全球科技、社交巨头Meta的V-JEPA。
有趣的是,在功能方面V-JEPA与Sora有很多相似之处,例如,都具备让AI学会如何通过自我监督学习认识、模拟世界,以提升生成视频的质量、表示学习方法和扩大视频训练数据范围。
可惜那天全世界的目光都聚焦在Sora身上,让图灵奖获得者,Meta首席科学家Yann LeCun s气的直跺脚,在社交平台上各种酸Sora的成果。
开源地址:https://github.com/facebookresearch/jepa
论文地址:https://ai.meta.com/research/publications/revisiting-feature-prediction-for-learning-visual-representations-from-video/

不过放眼全球,在开源领域有能力追赶OpenAI的Sora不超过5家公司。而Meta作为曾经成功复制ChatGPT的大模型开源鼻祖,相信他有能力再一次创造奇迹。
下面,「AIGC开放社区」将根据其公开的论文,为大家介绍一下这款“悄悄”发布的最新开源模型。
V-JEPA介绍
我们人类对世界的许多认知,特别是在生命的早期阶段都是通过视觉观察、总结获取的。
以牛顿的运动第三定律为例:即使是婴儿(或动物)在多次将物体从桌子上推下并观察结果之后,也能知道凡是上升的必将下降。你无需花费几个小时甚至阅读上千本书,就能总结出这个道理。
同理,Meta希望AI模型也能像人类那样,通过观察以及自我思考、总结,来获取对世界新事物的认识,最终学习并模拟他们。
所以,Meta基于Yann LeCun s提出的JEPA(联合嵌入预测架构)模型开发了非生成视频模型V-JEPA。
这是一种从视频中学习表示的自我监督方法,可以应用于各种视频、图像任务,而无需调整模型参数。
在图像分类、动作分类和时空动作检测任务的冻结评估中,V-JEPA超越了之前的视频表示学习方法。
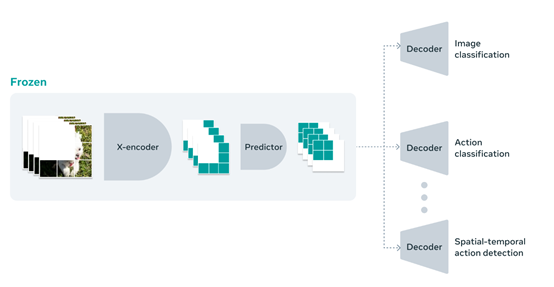
V-JEPA核心技术思路是,通过Transformer架构对视频序列进行编码,利用遮蔽自编码框架学习视频的关键特征表示。
再通过基于查询的特征池化模块提取与任务相关的重要特征,最终通过联合嵌入预测架构进行特征预测任务,以学习视频中不同时间步骤之间的语义关系。
因此,V-JEPA能够在无监督的情况下从大量未标记的视频数据中,学习到有用的特征表示,为生成高质量视频提供强大的预测、分析能力。
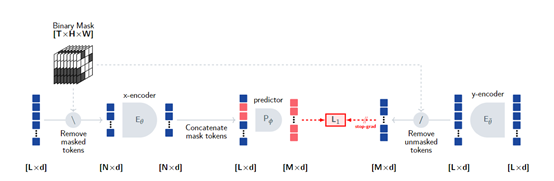
也就是说,即便你使用了没有标签的低质量视频训练数据集,通过V-JEPA模型也能轻松获取视频中的关键表示特征,这对于扩大视频训练数据范围帮助巨大。
V-JEPA主要功能模块
遮蔽自编码:V-JEPA中的核心模块之一,主要用于学习视频中的特征表示。当输入视频序列中的某些帧被随机遮蔽或删除后,模型需要通过观察其余的帧来预测被遮蔽的帧。
因此,模型被迫学习从上下文中推断出缺失信息的能力。遮蔽自编码可以促使模型学习到视频中的关键特征,并且通过预测遮蔽帧,模型还可以学习到不同时间步之间的依赖关系。
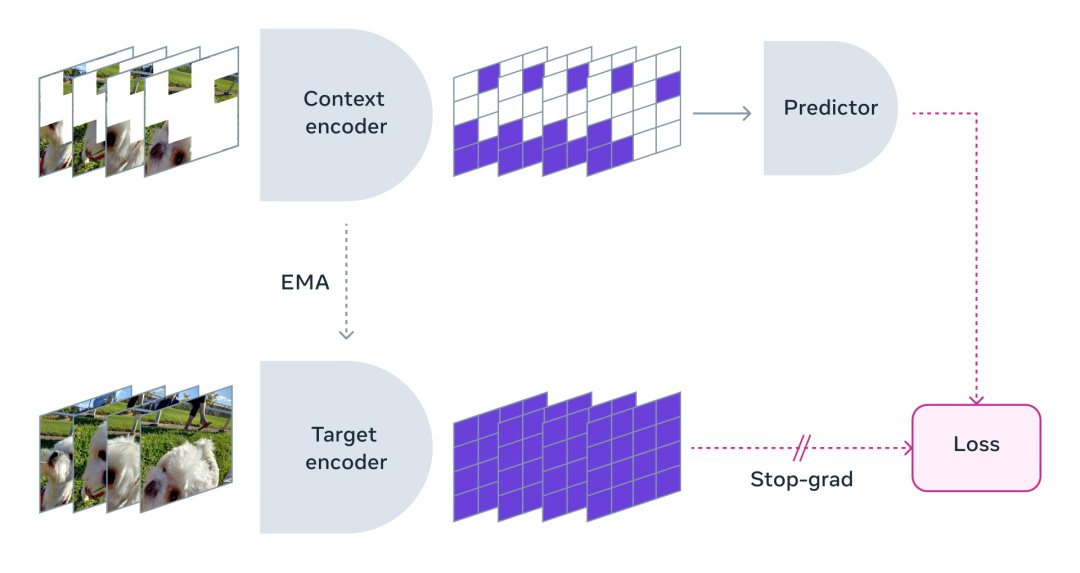
Transformer架构:在V-JEPA中,Transformer被用于建模视频序列中的时空关系。可以对输入序列中的每个时间步进行编码,并捕捉不同时间步之间的依赖关系。
Transformer的编码器由多个注意力头组成,每个头都可以学习不同的特征表示。所以,V-JEPA能够有效地建模视频中的时序信息,并将其用于特征预测任务。
JEPA:主要帮助V-JEPA模型,通过预测视频序列中不同时间步之间的特征嵌入,来学习视频中的特征表示。
模型将输入视频序列的不同时间步的特征进行编码,并通过自注意力机制捕捉它们之间的依赖关系。
然后,模型通过最小化预测特征嵌入,与实际特征嵌入之间的差异来进行训练。通过这种方式,使V-JEPA可以学习到视频中不同时间步之间的语义关系,并将其用于特征预测任务。
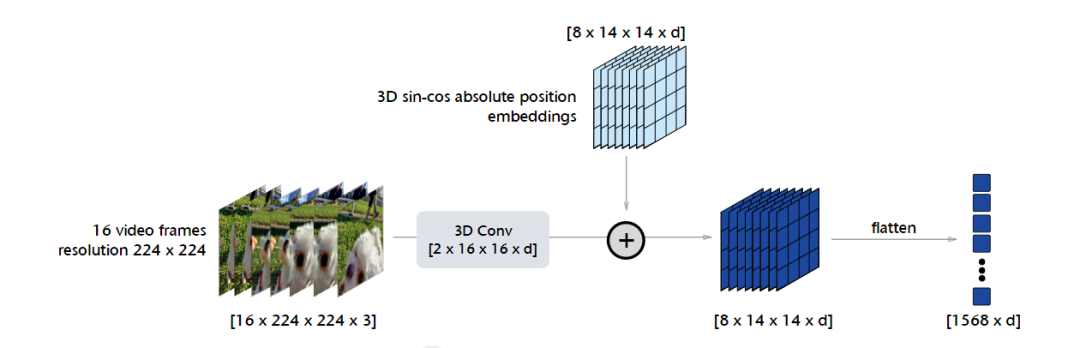
基于查询的特征池化:主要用于从视频序列中提取关键特征。在这个模块中,模型使用自注意力机制来选择视频序列中最相关的帧作为查询,并从这些帧中提取特征。
基于查询的特征池化使得V-JEPA能够提取丰富的、与任务相关的特征,并为后续的特征预测任务提供强大的特征表示。
V-JEPA的实验数据和未来应用场景
为了评估V-JEPA的性能,使用了冻结和端到端微调两种评估方法,并在多个图像和视频任务上进行了性能测试。
低样本量冻结评估:在Kinetics-400和Something-Something-v2数据集上,通过变化用于训练注意力探针的标签样本百分比,比较V-JEPA与其他视频模型在冻结评估中的表现。
使用训练集的5%、10%或50%,并在每种设置下取三个随机分割以获得更稳健的指标,为每个模型进行九次不同的评估实验。
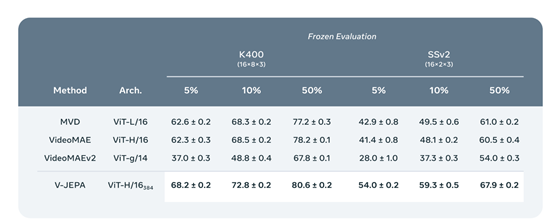
结果显示,V-JEPA在Kinetics-400任务上达到81.9%的准确率,在Something-Something-v2任务上达到72.2%,在ImageNet1K任务上达到77.9%,明显优于其他模型。
此外,V-JEPA模型还显示出在标记样本数量减少时更具优势,与像素重构模型相比性能更好。
V-JEPA模型中的“V”代表的是Video的意思,也就是说现阶段主要用于视频领域。
但Meta表示,下一步,将会把V-JEPA与音频相结合使用,并且可以充当早期的物理世界模拟器使用。
本文素材来源Meta官网,如有侵权请联系删除
END


本篇文章来源于微信公众号: AIGC开放社区



