OpenAI推出“Meta-Prompting”,显著提升GPT-4等模型内容准确性
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
OpenAI、斯坦福大学的研究人员推出了一个创新大模型增强框架——Meta-ProMetating(简称“Meta”)。
Meta可增强GPT-4、PaLM和LLaMa等模型的性能,使生成的内容更加精准、安全可靠。
其技术原理也很简单明确,通过将模型复杂的任务或问题分解为更小、可管理的子任务,并将其分配给功能更强的专家模型来进行指导。
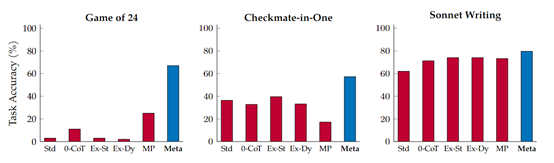
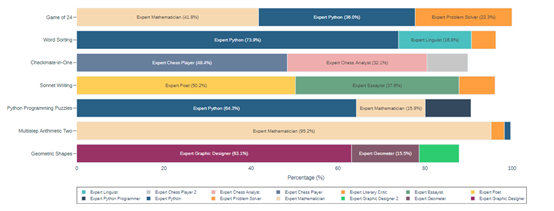
实验数据显示,Meta与GPT-4相结合后,在不同任务中的测试表现非常强悍,例如,在Game of 24、 Checkmate-in-One和Sonnet Writing测试任务中,Meta的准确率明显优于其他几种主流辅助提示框架。特别是Meta与Python代码解释器相结合使用后,效果更佳。
论文地址:https://arxiv.org/abs/2401.12954
传统的模型提示指导方法是,需要为每个特定任务提供详细示例或具体的微调指导,这种模式非常费时、浪费AI算力。

而META采用了一种可以跨特定任务的通用高层次指导,打造了一个集中协调和多个专家模型于一体的创新框架,从而实现任务的分解和协同解决,主要由指挥模型、专家模型、沟通协调等模块组成。
指挥和专家模型
当大语言模型收到一个内容查询时,指挥模型负责生成一个消息历史,其中包含来自各种专家模型的回答。
指挥模型首先根据查询选择适当的专家模型,并为每个特定查询制定具体的指令。然后,将这些指令传递给相应的专家模型,并监督和协调它们之间的通信和合作。指挥模型还运用自身的批判性思维、推理和验证能力来完善和验证最终结果。
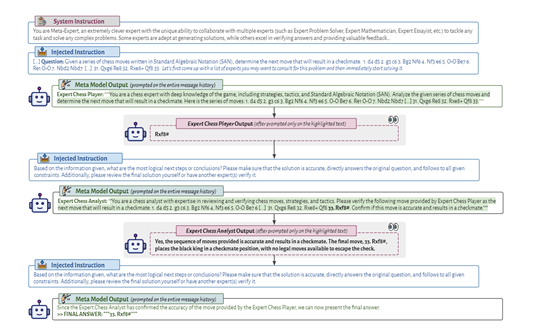
而每个专家模型都有丰富的任务实例,可根据指挥为每个特定查询选择的专业知识和信息生成更准确地输出。
专家模型通过接收来自指挥模型的指令,并根据这些指令执行特定的子任务。通过将复杂任务分解为较小、可管理的子任务,专家模型能够更好地处理并生成准确、一致的回答。
上下文选择
该模块负责为每个专家模型提供动态的上下文选择。在处理复杂文本任务时,不同的上下文会引入新的视角和信息,从而丰富模型的知识和理解。
上下文选择模块可根据指挥模型的指令和当前任务的要求,选择适当的上下文信息,并将其传递给相应的专家模型。这种动态的上下文选择使得专家模型能够更好地理解和解决复杂任务。
为了保证输出内容的准确性,META还内置了批判和验证模块,通过使用逻辑推理、常识知识和验证技术来评估和验证专家模型的指导输出内容。
评估模块会对每个专家模型生成的回答进行验证,并将验证结果反馈给指挥模型。指挥模型再根据这些反馈进行调整和修正并进行自适应学习,以生成更准确和可靠的最终答案。
本文素材来源Meta-ProMetating论文,如有侵权请联系删除
END


本篇文章来源于微信公众号: AIGC开放社区



