Llama-3公布基础训练设施,使用49,000个H100
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
3月13日,社交、科技巨头Meta在官网公布了两个全新的24K H100 GPU集群(49,152个),专门用于训练大模型Llama-3。
此外,Llama-3使用了RoCEv2网络,基于Tectonic/Hammerspace的NFS/FUSE网络存储,继续使用了PyTorch机器学习库。
从训练进度来看,估计Llama-3最快将于4月末或5月中旬上线。受Sora影响,很可能是一个多模态模型,并且会继续开源。
Meta表示,预计到2024年底,将拥有600,000个H100的算力。

Meta首席科学家确认
Meta庞大的AI算力集群
Meta作为全球市值最高的科技公司之一,对AI的投入一直非常大,致力于构建造福全人类的AGI(通用人工智能)。
早在2022年1月24日,Meta首次公布了AI 研究超级集群(RSC)的详细信息,拥有16,000个英伟达A100 GPU。
该集群在开发全球最受欢迎的类ChatGPT模型Llama和Llama 2,以及计算机视觉、NLP 和语音识别、图像生成等发挥了重要作用。

本次新增的GPU集群建立在RSC成功经验之上,每个集群包含24,576 个H100 GPU,能够支持比以往更复杂、参数更高的大模型训练。
集群网络
Meta每天要处理数百万亿次AI模型的请求,所以,使用一个高效、灵活的网络才能保证数据中心安全、稳定的运行。
一个集群是基于Arista7800、Wedge400和Minipack2 OCP 机架交换机,构建了一个具有融合以太网远程直接内存访问(RoCE) 网络结构的解决方案;
另外一个使用了NVIDIA Quantum2 InfiniBand结构,这两种方案都能互连 400 Gbps端点。

在两个不同集群帮助下,Meta可以评估不同类型的互联对大规模训练的适用性和可扩展性,为以后设计和构建更大、更大规模的集群提供更多经验。
此外,Meta已经成功地将 RoCE 和InfiniBand 集群用于大型生成式AI工作负载(包括正在RoCE 集群上对 Llama 3 进行的训练),并且没有出现任何网络瓶颈。
硬件平台
新增的两个集群全部使用Grand Teton,这是Meta内部设计的开放性 GPU 硬件平台,于2022年10月18日首次发布。

Grand Teton 建立在多代人工智能系统的基础上,将电源、控制、计算和结构接口集成到一个机箱中,以获得更好的整体性能、信号完整性和散热性能。具有简化的设计、灵活性,可快速部署到数据中心机群中,并易于维护和扩展等优点。
数据存储
随着大模型的功能趋于多模特,需要消耗大量的图像、视频、音频和文本数据,所以,对数据存储的需求迅速增长。
Meta新集群的存储部署通过自创的用户空间 Linux 文件系统API来满足人工智能集群的数据和检查点需求,该应用程序接口由 Meta 针对闪存媒体进行了优化的 Tectonic 分布式存储解决方案版本提供支持。
该解决方案使数千个 GPU 能够以同步方式保存和加载检查点(这对任何存储解决方案来说都是一个挑战),同时还提供了数据加载所需的灵活、高吞吐量的外字节级存储。
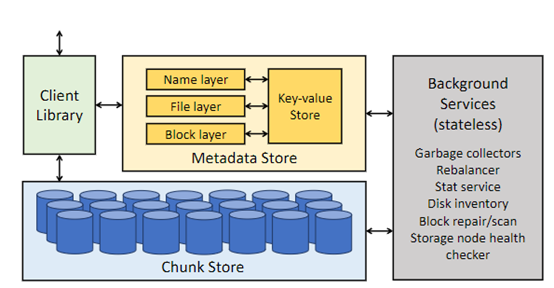
Meta还与 Hammerspace 合作,共同开发、部署并行网络文件系统 (NFS),以满足开发人员对超级AI集群的存储要求。
此外,Hammerspace 还能让工程师使用数千个 GPU 对作业进行交互式调试,因为环境中的所有节点都能立即访问代码更改。
将Meta的 Tectonic 分布式存储解决方案和 Hammerspace 结合在一起,可以在不影响规模的情况下实现快速功能迭代。
本文素材来源Meta官网,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



