独家支持MoE大模型一键训练,达观大模型管理平台两大全新功能发布
添加书签
DATAGRAND
在当下MoE架构模型可能成为主流趋势的背景下,达观大模型管理平台为了满足用户多样化模型管理需求,此次带来了2大内容更新,除了更大参数量级的70B曹植模型,更重量级的是上线全新曹植MoE模型,独家支持在平台上完成MoE大模型私有化部署、一键训练。
支持用户对曹植MoE模型进行和常规模型同样的SFT微调、模型量化(支持INT8、INT4、INT3、INT2)、封装服务接口、Prompt指令定制等运维流程,曹植MoE模型相比Mixtral更优的特点在于曹植MoE模型不光支持多语种,而且全面支持中文(Mixtral 8x7B不支持中文),并在中文场景做了针对性的训练优化,使得模型在长文本、多语种或众多垂直场景中发挥出更优、更强劲的性能。
曹植MoE模型全新上线
DATAGRAND
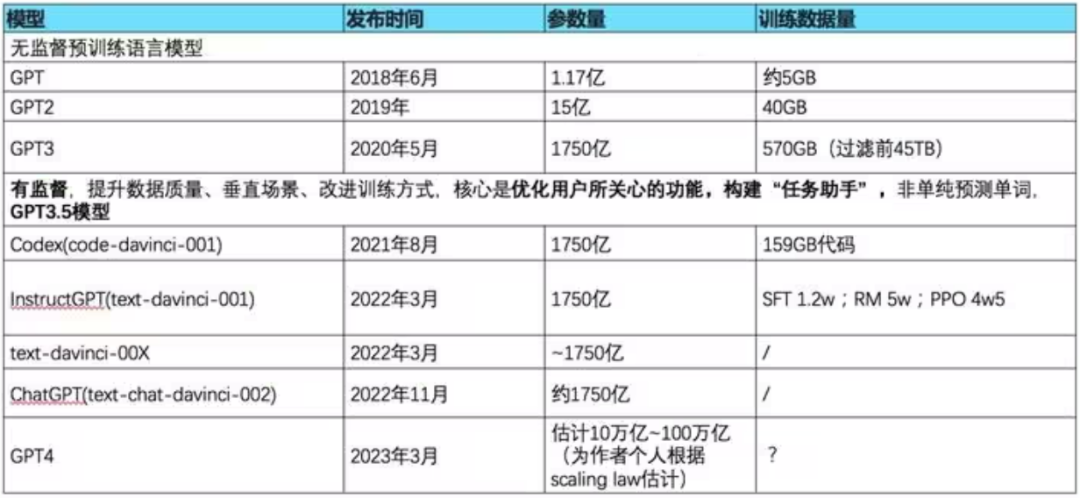
历代gpt模型参数概览
随着MoE架构的崭露头角,我们看到了一种新的可能性,即通过组合多个中等规模的模型,同样能够达到更大模型的效果。最近在大模型开源社区中备受瞩目的,除了采用与Gemini相同技术构建的Gemma,另一个备受关注的模型便是Mixtral 8x7B。这个由一家法国公司推出的新架构模型在推出后迅速引起了巨大的讨论。
DATAGRAND
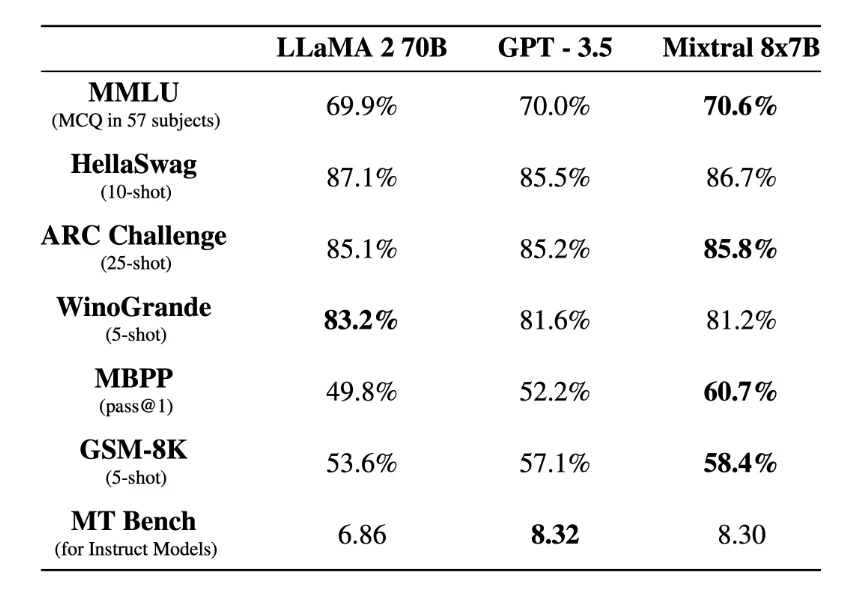
Mixtral 8x7B性能测试
DATAGRAND
什么是MoE?
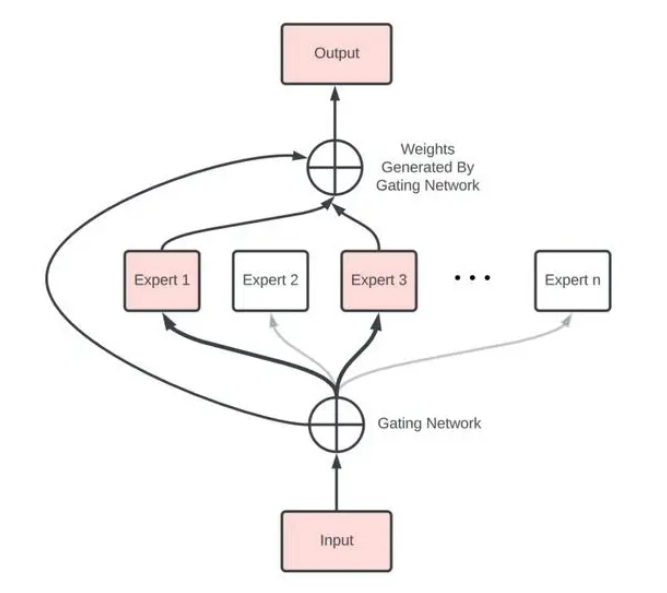
MoE结构
DATAGRAND
-
专家(Expert):MoE层由许多专家、小型MLP或复杂的LLM(如 Mistral 7B)组成。
-
路由器(Router):路由器确定将哪些输入token分配给哪些专家。
路由策略有两种:token选择路由器或路由器选择token。
路由器使用softmax门控函数通过专家或token对概率分布进行建模,并选择前k个。
DATAGRAND
MoE能够带来的好处
-
每个专家都可以专门处理不同的任务或数据的不同部分。
-
MoE构架能向LLM添加可学习参数,而不增加推理成本。
-
可以利用稀疏矩阵的高效计算
-
并行计算所有专家层,以有效利用GPU的并行能力
-
帮助有效地扩展模型并减少训练时间。以更低的计算成本获得更好的结果!
DATAGRAND

数据集管理
模型训练
END



本篇文章来源于微信公众号: AIGC开放社区



