英伟达推出NIM,可优化推理以实现大规模AI模型部署
添加书签
专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
ChatGPT的出现大幅度加速了生成式AI的开发、应用进程。为了帮助开发者加速部署、推理进程,英伟达(NVIDIA)推出了NVIDIA NIM。
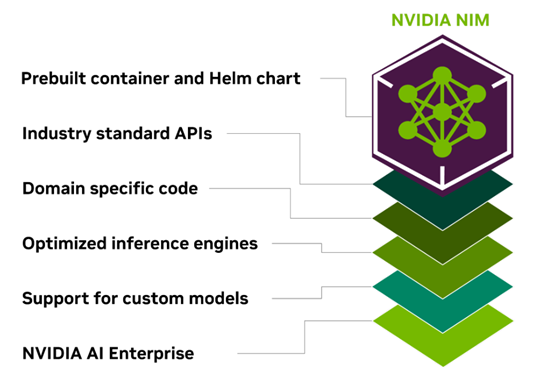
NVIDIA NIM是一组经过优化的云原生微服务,旨在缩短上市时间并简化在云端、数据中心和GPU加速工作站上部署生成式AI模型。通过使用行业标准的API,将AI模型开发和打包的复杂性抽象化,从而扩大AI模型开发人员的范围。

NVIDIA NIM旨在弥合人工智能开发的复杂世界与企业环境的运营需求之间的鸿沟,使得10-100倍更多的企业应用开发人员能够参与其公司的人工智能转型。
NIM专为可移植性和控制而构建,可实现模型在各种基础设施上部署,从本地工作站到云端到本地数据中心。这包括NVIDIA DGX、NVIDIA DGX Cloud、NVIDIA认证系统、NVIDIA RTX工作站和个人电脑。
预构建的容器和打包优化模型的Helm图表已在不同的NVIDIA硬件平台、云服务提供商和Kubernetes发行版上进行了严格验证和基准测试。这使得支持覆盖了所有基于NVIDIA的环境,并确保组织可以在任何地方部署其生成式人工智能应用程序,保持对其应用程序和处理的数据的完全控制。
NIM通过针对每个模型和硬件设置进行优化的推理引擎,为加速基础设施提供最佳的延迟和吞吐量。这降低了推理工作负载的成本,并改善了最终用户的体验。
NIM支持多种AI模型,如社区模型、NVIDIA AI基金会模型和NVIDIA合作伙伴提供的定制AI模型,可支持多个领域的AI用例。这包括大语言模型、视觉语言模型(VLMs)以及语音、图像、视频、3D、药物发现、医学成像等模型。
开发人员可以使用NVIDIA API目录中的NVIDIA托管的云API来测试最新的生成式人工智能模型。或者他们可以通过下载NIM自行托管模型,并在主要云提供商或本地部署Kubernetes,以用于生产环境,从而缩短开发时间、降低复杂性和成本。
NIM 微服务通过打包算法、系统和运行时优化,并添加行业标准的 API,简化了 AI 模型部署过程。这使开发人员能够将 NIM 集成到其现有的应用程序和基础设施中,而无需进行大量定制或专业知识。
通过NIM,企业可以优化他们的AI基础设施,实现最大效率和成本效益,而无需担心AI模型开发复杂性和容器化。除了加速AI基础设施,NIM还有助于提高性能和可扩展性,同时降低硬件和运营成本。
对于希望为企业应用定制模型的企业,NVIDIA提供了跨不同领域的模型定制微服务。NVIDIA NeMo提供了使用专有数据进行大语言模型、语音AI和多模态模型微调的能力。
NVIDIA BioNeMo通过不断增加的生成生物化学和分子预测模型集合加速了药物发现。NVIDIA Picasso通过Edify模型实现更快的创意工作流程。这些模型是在视觉内容提供商的许可库上训练的,从而实现了定制生成式AI模型用于视觉内容创作的部署。
本文素材来源英伟达官网,如有侵权请联系删除
END


本篇文章来源于微信公众号: AIGC开放社区



