3140亿参数,可商用!马斯克开源大模型Grok-1
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
根据其公布的测试数据显示,性能超过了GPT-3.5、LLaMA 2 70B,弱于GPT-4、Claude 2、Palm 2等闭源模型。
开源地址:https://github.com/xai-org/grok-1
磁力地址:magnet:?xt=urn:btih:5f96d43576e3d386c9ba65b883210a393b68210e&tr=https%3A%2F%2Facademictorrents.com%2Fannounce.php&tr=udp%3A%2F%2Ftracker.coppersurfer.tk%3A6969&tr=udp%3A%2F%2Ftracker.opentrackr.org%3A1337%2Fannounce

专家混合模型简单介绍
MoE模型全称为Mixture of Experts,其核心原理是将一个庞大的神经网络分解为多个相对独立的小型子网络(即专家),每个专家负责处理输入数据的某些方面。
MoE模型通过一个门控机制根据输入数据选择性地组合不同专家的输出,从而产生最终的输出。
这种架构设计使得MoE模型能够高效利用计算资源,避免对所有参数进行无谓的计算。主要包括门控制机制、专家网络和聚合器三大模块
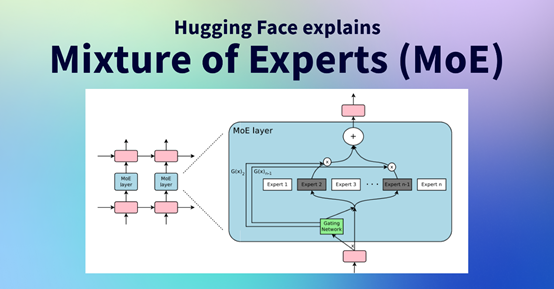
门控机制(Gating Network):这是MoE模型的核心模块,负责决定每个输入应该由哪个或哪几个专家处理。
门控机制会根据输入数据的特征分配权重给不同的专家,这个过程是动态的,意味着不同的输入会根据其内容被分配给最合适的专家处理。例如,Grok-1模型中只有大约25%的参数被实际使用或“激活”。
专家网络(Experts):这些是模型中的子网络,每个都有自己特定的参数配置。在传统的MoE模型中,这些专家网络可以是结构相同但参数不同的多个神经网络。每个网络都专注于模型任务的一个方面或输入数据的一个子集。
聚合器(Aggregator):一旦各个专家给出了自己对于输入的处理结果,聚合器则负责将这些结果综合起来,形成最终的输出。聚合的方式可以是简单的加权和、投票机制或者更复杂的融合策略。
MoE是开发、训练超过千亿参数大模型常用的架构,例如,GPT-4、Palm 2使用的都是该架构。
Grok-1简单介绍
x.ai表示,在2023年10月使用基于 JAX 和 Rust 的自定义训练堆栈从头开始训练了Grok-1模型,没有被进一步优化来执行任何特定的任务。这意味着该模型具有广泛的应用潜力,适用于不同的行业。
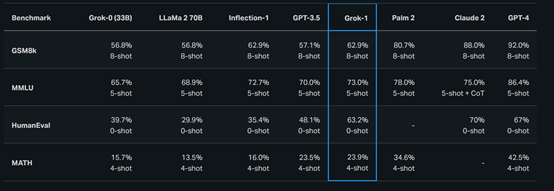
性能测试方面,在GSM8k、MMLU、HumanEval等多个测试平台显示,在8-shot、5-shot等状态下,其性能全面超过了LLaMA 2-70B、GPT-3.5、Grok-0 33B和Inflection-1。但与Palm 2、Claude 2、GPT-4还有较大的距离。
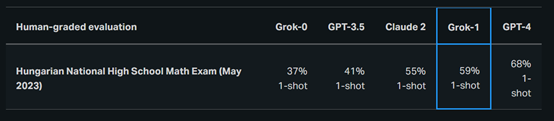
由于这些基准测试是公开的,Grok-1的训练数据可能已经包含了测试答案。开发团队使用了2023年匈牙利全国高中决赛的数学题对Grok-1、Claude 2、GPT-4进行了人工测试。
结果显示,Grok-1 以 C (59%) 的成绩通过了考试,而 Claude-2取得了差不多的成绩 (55%),GPT-4 以 68% 的成绩获得了B。
训练数据方面,Grok-1 发布版本所使用的训练数据截至 2023 年第三季度的互联网数据以及xAI人工智能导师提供的数据。
局限性,虽然 Grok-1 的性能非常出色,但也会出现虚假、幻觉等情况,同时Grok-1不具备独立搜索网络的能力,不是一个多模态的模型。
本文素材来源Grok-1官网,如有侵权请联系删除
END


本篇文章来源于微信公众号: AIGC开放社区



