微软推出VASA-1:可生成会说话的,动态人物视频
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
微软亚洲研究院推出了VASA-1,用户只需要输入一张图片和一段音频,就能生成表情丰富、细节逼真的动态人物视频。
根据其demo演示的效果,能以45fps 生成 512×512 分辨率的视频帧,在线流媒体环境中可以支持高达 40fps 的帧率。
而延迟只有170ms左右,并且只需一张英伟达的4090 GPU即可,整体性能非常高效。
论文地址:https://arxiv.org/abs/2404.10667
VASA-1的demo演示
早在今年2月末,阿里巴巴的研究人员便发布了一款类似的视频模型EMO,通过一张图片、音频就能生成实时会说话的人物视频,成功将张国荣、奥黛丽赫本等名人“复活”,当时在AI圈内引起了很大的反响。
EMO生成的张国荣唱歌视频
随后,清华大学、东京大学、庆应义塾大学等联合开源了EMAGE;华为、腾讯开源了AniPortrait;谷歌推出了VLOGGER模型,在生成效果方面基本与EMO差不多。
再加上微软本次推出的VASA-1,可以充分说明人物视频合成领域已经受到了广泛的关注,并且很大的应用空间。
例如,前几天的“AI刘强东”在直播带货便小火了一把,引发上千万人围观,销售额甚至超过了一些头部真人大主播。这种数字人主播便离不开EMO、VASA-1这类技术的加持。
构建面部潜在空间
传统的人物合成视频,通常会将嘴唇运动、面部表情、眼睛凝视和眨眼等面部动态分开处理,这样做虽然可以精准捕获面部细节,但在合成阶段会出现不协调、抽搐、算力成本高等缺点。
而VASA-1对面部动态和头部运动进行了综合建模,将所有这些面部动态视为一个单一的潜在变量,并通过视频数据训练了一个表达丰富且解耦的面部潜在空间,能够以更低的资源消耗捕捉到人类面部的细微表情和头部动作,从而生成逼真、表情丰富的动态人物视频。
VASA-1生成的视频
为了构建面部潜在空间,VASA-1使用基于3D的辅助表示,并结合了一系列损失函数。
该方法能够在大量面部视频数据上进行自监督或弱监督训练,从而学习到具有高度解耦和表达性的面部潜在表示。这种表示不仅能够捕捉到丰富的面部动态细节,还能够在生成过程中提供有效的控制。

此外,VASA-1能够接受一组可选的控制信号,包括脸部凝视方向、头部到相机的距离,可以使得生成的面部表情,根据特定的业务场景需求进行动态调整,例如,直播带货、博物馆讲解、虚拟导游等。
音频驱动面部生成
音频在生成说话人物视频方面非常重要,不仅包括嘴唇的运动与音频同步,还涉及到面部表情、眼睛的转动以及其他非语言的动态行为与其相匹配。
VASA-1使用了一个扩散模型从输入的音频中提取特征,包括音高、音量、语调等。然后使用扩散变换器,根据提取的音频特征生成面部动态的潜在代码。
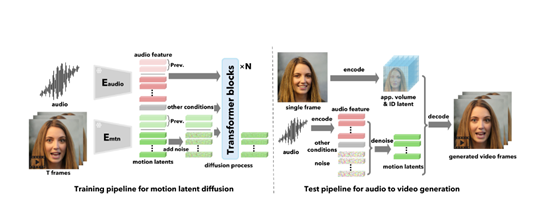
同时将额外的条件信号,例如,凝视方向、情感偏移、语速等,与音频特征一起输入到扩散变换器中,再通过生成的面部动态潜在代码和预先训练好的面部解码器,渲染出与音频同步的实施人物说话视频。
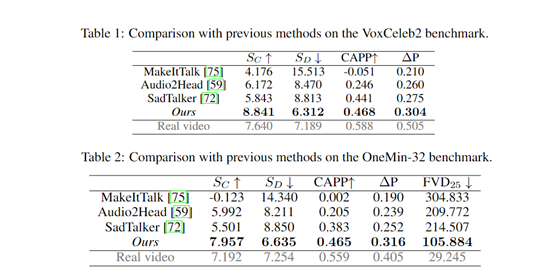
研究人员在VoxCeleb2、OneMin-32基准测试中对VASA-1进行了综合测试。结果显示,VASA-1在音频-唇部同步分数上表现最佳;SC和SD分数均高于其他模型,且接近真实视频的表现。
本文素材来源微软官网、VASA-1论文,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



