超越DPO,创新大模型优化算法SimPO
添加书签
专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
随着ChatGPT等模型的影响力越来越大,如何根据人类反馈优化大模型的性能,实现超级对齐降低非法内容输出变得非常重要。
传统的DPO(直接偏好优化)是使用较多的离线偏好优化算法,主要通过重新参数化奖励函数,从人类反馈中学习以优化大模型。但是DPO的奖励函数依赖于一个参考模型,不仅会大幅度增加AI算力和内存需求,在训练和推理过程中的度量会出现不一致等情况。
所以,弗吉尼亚大学和普林斯顿大学的研究人员推出了更好的优化方法SimPO。
论文地址:https://arxiv.org/abs/2405.14734
Github地址:https://github.com/princeton-nlp/SimPO

SimPO是在DPO的基础之上进行了创新,通过采用序列的平均对数概率作为隐式奖励机制,这一巧妙的设计与模型生成过程紧密相连,同时消除了对参考模型的依赖,极大提升了了计算效率和内存使用率。
此外,SimPO还提出了一个“目标奖励边际”的概念,将其嵌入到布拉德利-特里比较模型中,这个边际设定使得胜出的模型响应与失败的响应之间形成更大的差距,可有效增强算法的区分度进一步优化分类效果,使得模型的输出内容更加符合人类的偏好。
自由奖励函数
DPO优化方法的奖励函数的构建依赖于一个参考模型,通常是一个经过监督微调的模型。这也是致使其大幅度增加算力、内存的主要原因。SimPO通过自由奖励函数可以有效解决这些难点。
自由奖励函数不再依赖于任何外部的参考模型,而是直接使用策略模型本身来计算奖励。SimPO将奖励函数定义为序列中所有标记的对数概率的平均值,公式如下:

这种设计使得奖励函数与模型生成过程中使用的度量(即平均对数似然)直接对齐,从而确保了模型在生成响应时能够更加精确地优化目标。
此外,SimPO的奖励函数还引入了长度归一化的技术概念。在生成任务中,序列的长度往往会对模型的生成质量产生影响。如果不对长度进行归一化处理,模型可能会倾向于生成较短或较长的序列,不符合用户对生成质量的期望。

通过将奖励函数除以序列长度,SimPO确保了奖励与序列长度无关,避免了模型在生成过程中对长度的过度依赖。
SimPO实验数据
为了评估、验证SimPO的性能,研究团队在多种模型的预训练下进行了广泛的比较实验,涵盖基础模型和指令微调模型,例如,非常出名的Mistral系列和Llama3等。特别是在评估指标上,他们选取了AlpacaEval 2、MT-Bench以及最近推出的具有挑战性的Arena-Hard基准测试。
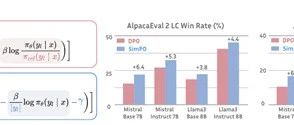
结果显示,无论是在哪项测试中,SimPO均展现出了优于DPO及同类技术的优化性能。在AlpacaEval 2上,SimPO的提升幅度最大可达6.4分,而在Arena-Hard上,这一数值更是达到了7.5分,充分证明算法的高效性。
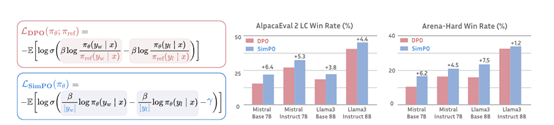
值得一提的是,基于Llama3-8B-Instruct构建的模型,在应用SimPO算法后,在AlpacaEval 2上的表现达到了惊人的44.7%的控制长度胜率,超越了排行榜上的Claude 3 Opus,同时在Arena-Hard上也取得了33.8%的胜率,成为高性能的80亿参数开源大模型。
本文素材来源SimPO论文,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



