Anthropic API新增提示缓存功能:成本降低90%,延迟降低85%
添加书签
专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
著名大模型平台Anthropic的API新增提示缓存(Prompt Caching)功能,可以帮助开发人员轻松缓存API调用之间经常使用的上下文,同时能将长提示的成本降低90%,延迟降低85%。
目前,新的API提示缓存功能已经支持Claude 3.5 Sonnet 和 Claude 3 Haiku模型,很快会也会支持Claude 3 Opus。
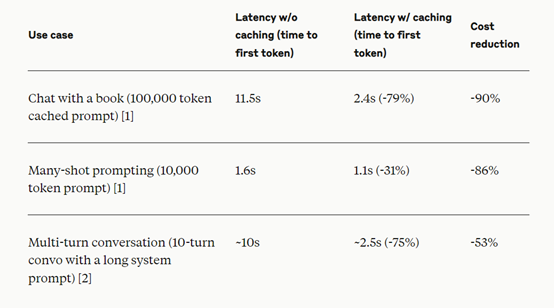
提示缓存的工作原理非常简单,当用户发送一个启用提示缓存的请求时,系统首先检查提示前缀是否已经从最近的查询中缓存。
如果找到了,它就使用缓存版本,从而减少了处理时间和成本;如果没有找到,它就处理完整的提示并缓存前缀以供将来使用。
这对于包含许多示例的提示、大量的上下文或背景信息、具有一致指令的重复任务、以及长多轮对话都非常有用。缓存的生命周期为5分钟,每次使用缓存内容时都会刷新。

所以,提示缓存功能特别适用于需要大量上下文的场景,例如,开发AI Agent、编码助手、大型文档助手、详细指令集的共享,以及生成式AI搜索等。
开发者通过提示缓存可以减少长时间对话的成本和延迟,改善自动完成和代码库问答,将完整的长篇材料纳入提示而不增加响应延迟,分享广泛的指令和示例以微调响应,以及提高多轮工具调用和迭代更改场景的性能。
用一个具体的例子来为大家解读一下提示缓存是如何实现的,假如我们使用Messages API,并且整个《傲慢与偏见》的文本通过cache_control参数被缓存。
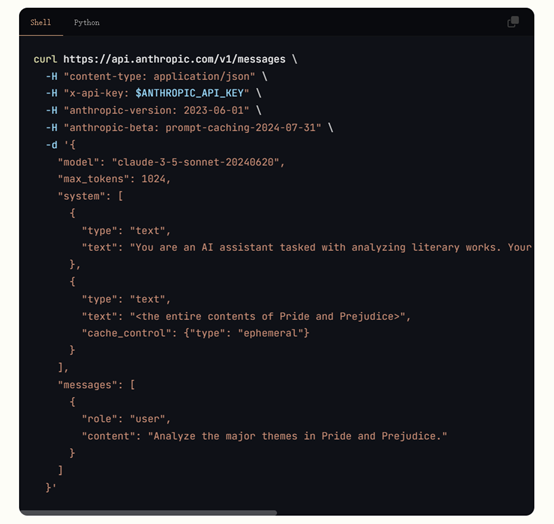
这样,就可以在多个API调用中重用这个大文本,而不需要每次都重新处理它。只需更改用户消息,就可以在利用缓存内容的同时,提出关于这本书的各种问题,从而实现更快的响应和提高效率。
如果在提示缓存中遇到意外行为,确保跨调用的缓存部分是相同的,检查调用是否在5分钟的缓存生命周期内进行,并验证tool_choice.type和图像使用在调用之间是否保持一致。需要注意的是,tool_choice.type的更改或提示中任何地方图像的存在/缺失都将使缓存失效,需要创建新的缓存条目。
开发者还可以监控缓存性能,使用API响应字段中的usage来跟踪缓存创建和读取的token数量。根据实际使用场景,可以定制不同的前缀缓存策略。

在用户的提示中,将静态内容系统指令、上下文、工具定义放在开头,并使用cache_control参数标记可缓存内容的结束。最多可以定义4个缓存断点,允许分别缓存不同的可重用部分。
为了有效使用缓存,最佳实践包括缓存稳定、可重用的内容,将缓存内容放在提示的开头以获得最佳性能,战略性地使用缓存断点来分隔不同的可缓存前缀部分,并定期分析缓存命中率以调整策略。
在定价方面,提示缓存引入了新的定价结构。例如,Claude 3.5 Sonnet模型的基本输入token价格为每千个输入token为3美元,缓存写入价格为每千个输入token为3.75美元;
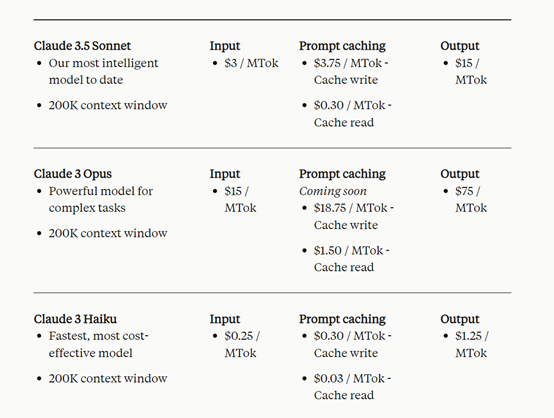
缓存命中价格为每千个输入token为0.30美元,输出token价格为每千个输出token为15美元。值得注意的是,缓存写入token比基本输入token贵25%,而缓存读取token则比基本输入token便宜90%。
本文素材来源Anthropic,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



