每天免费100万token,GPT-4o新增微调功能
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
OpenAI向所有开发者推出GPT-4o数据微调功能,可以使用自己的数据打造准确率、输出模式更好的个性化ChatGPT助手。
例如,韩国最大电信运营商SK Telecom通过OpenAI的数据微调功能,打造了特定的AI助手,使对话总结准确率提高了35%,意图识别率提升了33%,客户满意度大幅度提升。
同时OpenAI宣布从今天到9月23日,每天免费提供100万token微调额度,推理成本每100万token输入3.75美元,每100万token输出15美元。

什么是数据微调
通常大模型是在超大规模数据上进行预训练的,以学习通用的语言知识和输出模式。由于数据过于杂乱,模型可能在金融、法律、医疗等业务中的表现并不理想,因为没有针对特定领域进行专门优化。
而数据微调可以将与特定任务或领域相关的新数据融合到模型中,并使用这些数据来调整模型的参数,使模型能够更好地理解和处理这些特定的数据。
在微调过程中,将收集到的特定任务数据输入到预训练模型中,然后通过反向传播、梯度下降、监督学习等技术,调整模型的参数使其在特定任务上的表现优化,模型会逐步学会识别和处理特定任务的数据模式。
例如,GPT-4o模型只能生成一般性的宽泛文本,但我们想要将其应用于情感分析领域,以判断文本的情感倾向是积极、消极还是中性。
我们就可以收集大量带有情感标注的文本数据,并使用这些数据对模型进行微调。在微调过程中,模型可以更好地学习如何根据文本中的词汇、语法和语义信息来判断情感倾向。
实际微调案例
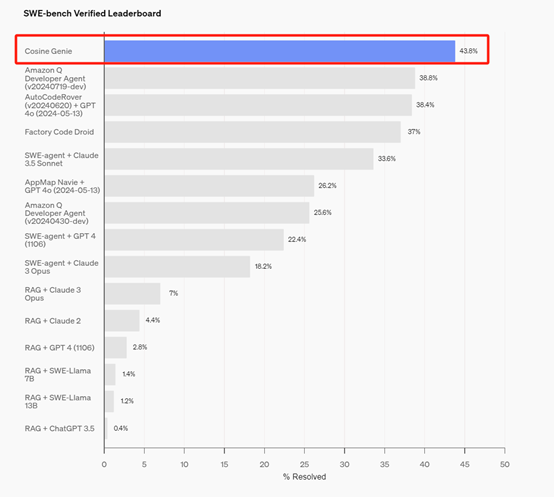
Genie是上周 AI Agent代码领域杀出的一匹大黑马,其性能超过了同类的Devin、Amazon Q、Swe-agent+GPT-4等,而该产品便是基于Genie自有数据在GPT-4o上微调而成。
Genie能够实现跨复杂平台端到端的进行推理,能够像人类那样来修改和检测代码。在GPT-4o的帮助下,Genie 在OpenAI新发布的SWE-bench Verified 基准测试中实现了 43.8% SOTA得分。还在 SWE-bench Full 基准测试中取得了 30.08% 的得分,也是目前最高的评分。
Harvey是一家专门为律师提供类ChatGPT助手的服务商,为了更好的提升法律内容输出与准确率,使用了OpenAI的GPT-4进行数据微调。
在微调的过程中,他们使用了10亿token的数据,并对模型训练过程的每一步都进行了修改。最终,该AI助手的回答准确率提升了83%,使得律师们更喜欢这种微调的助手。
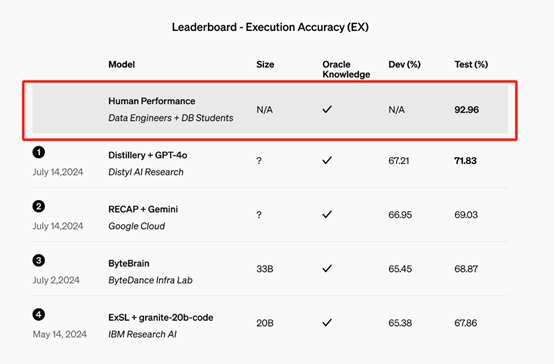
Distyl是一家为财富500强企业提供 AI 解决方案的合作伙伴,最近在 BIRD-SQL 基准测试中获得了第一名,这是领先的文本到 SQL 基准测试。
Distyl的微调 GPT-4o 模型在排行榜上实现了 71.83% 的执行准确率,并在查询重构、意图分类、思维链和自我纠正等任务中表现出色,尤其是在 SQL 生成方面表现尤为突出。
本文素材来源OpenAI,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



