谷歌发布Imagen 3,超过SD3、DALL・E-3
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
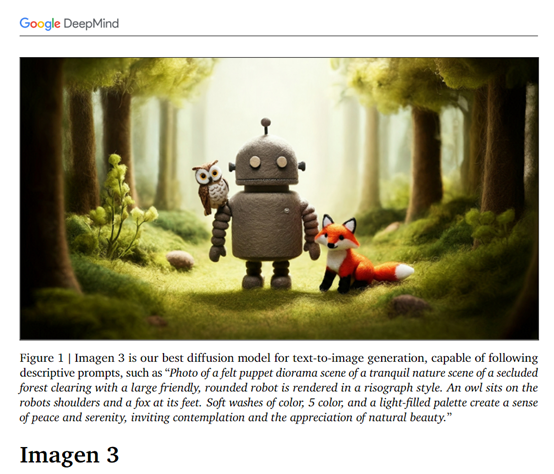
谷歌DeepMind发布了全新文生图模型Imagen 3,在文本语义还原、色彩搭配、文本嵌入、图像细节、光影效果等方面相比第二代大幅度提升。
Imagen 3的评测效果也比SD3、DALL・E-3、Midjourney等知名开闭源模型更好。目前,Imagen 3已经可以在美国地区使用,未来谷歌会持续扩大使用范围。
论文地址:https://arxiv.org/abs/2408.07009
传统的扩散模型通常从随机噪声开始,然后通过一系列迭代步骤逐步恢复图像的真实细节。但在处理高维复杂数据、图像质量和多样性以及训练稳定性方面有一些缺点,同时开发成本也比较高,而谷歌的Imagen 3使用了潜空间扩散模型。
潜空间是指一个被压缩的表示形式,模型可以在这个表示形式中进行操作,而不是直接在原始图像像素上进行。使得Imagen 3 更容易处理高分辨率图像,因为它避免了直接在像素级进行复杂的计算,而是专注于学习图像的高级特征表示。
所以,在Imagen 3模型中,数据不再是静态的实体,而是被视为一个动态的、随时间演变的过程。这个过程从数据的清晰状态开始,逐渐向混沌状态过渡,将数据点推向一个模糊不清的潜空间。然后,模型需要逆转这一过程,从充满噪声的潜空间中,逐步恢复出清晰的数据图像。

简单来说,就像一位艺术家在创作一幅画,首先在画布上随意涂抹颜料,然后逐渐勾勒出清晰的轮廓和细节。潜空间扩散模型正是以这样的逆过程,从混沌中寻找秩序,从噪声中提炼出有意义的信息。
潜空间扩散模型为Imagen 3带来了三大显著的技术优势:1)极大地提升了图像的生成质量。传统模型在生成高分辨率图像时,往往难以平衡图像的细节和整体的一致性。而Imagen 3通过潜空间的逆向过程,能够在保持图像细节的同时,生成高分辨率、高清晰度的图像。
2)潜空间扩散模型在处理复杂文本提示时表现出了卓越的能力。不仅能够理解文本的基本含义,还能够捕捉到文本中隐含的细微差别和深层含义,从而生成与文本描述高度一致的图像。
3)潜空间扩散模型的逆向生成过程为模型提供了更多的创新空间。在逆扩散过程中,模型可以探索不同的图像生成路径,从而生成出更加多样化和具有创新性的图像。这种创新性不仅体现在图像的多样性上,还体现在模型能够根据文本描述创造出全新的视觉内容。
训练过程方面,Imagen 3在大规模且丰富的数据集上进行了预训练,使得模型能够学习到图像内容和文本描述之间的复杂关联。随后,模型通过多阶段的扩散过程,学习如何在潜空间中表示这些图像和文本,包括学习如何将图像和文本映射到一个共同的潜在空间,并在引入噪声后,如何将数据点从清晰状态转变为模糊状态,最终在逆向过程中从噪声中恢复出清晰的图像。
以下是Imagen 3生成的图片欣赏。





为了评估 Imagen 3 的性能,团队将其与其他先进的模型进行了对比,包括 Imagen 2、DALL・E-3、Midjourney v6、SD3和 Stable Diffusion XL 1.0。通过广泛的人类评估和基准测试评估,Imagen 3 在多个方面展现出了卓越的性能。
例如,在 GenAI – Bench 数据集上,Imagen 3 明显比 DALL・E 3、Midjourney v6、SD3和SDXL 1等模型更受用户青睐。
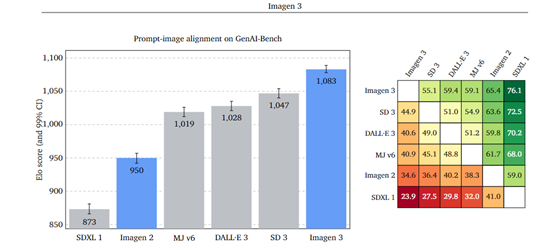
在提示 – 图像对齐方面,Imagen 3 表现出了极强的能力,能够准确地将输入的文本提示转化为相应的图像内容。与DALL・E-3等他模型相比,对提示的理解更为精准,生成的图像能够更紧密地贴合提示的意图,无论是对于简单明了的提示,还是复杂详细的提示,Imagen 3 都能展现出较强的理解和生成能力。
本文素材来源Imagen 3 论文,如有侵权请联系删除
END




本篇文章来源于微信公众号: AIGC开放社区



