OpenAI将在两周内发布“草莓”模型,推理模式非常特殊!
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
Theinformation消息,OpenAI将在未来两周内发布最新模型“草莓”( Strawberry) ,会为ChatGPT等产品提供技术支持。
据测试过该模型的人员透露,草莓模型的推理模式非常特殊,可以像人类一样在提供响应之前进行拟人化思考,用10—20秒的时间进行信息搜索、评估,更高效的利用现有AI算力提供更准确的内容。
其实,草莓的这种特殊的推理模式,谷歌DeepMind就专门出过一篇论文进行过类似的技术介绍。
目前,多数大模型的性能受限于其预训练阶段所获取的数据集,以及推理过程中的算力资源。研究人员发现,可以通过更多的推理时间、自适应(就是草莓的特殊延迟推理)来提升模型的性能,这种技术称为——测试时计算(Test-time computation)。
根据提示的难度不同,优化方法主要有两种:一种是基于密集型、流程导向的验证奖励模型进行搜索;另一种是在给定提示下,自适应地更新模型对响应的概率分布。

密集型、流程导向的验证奖励模型搜索主要通过引入一个能够评估模型生成答案步骤正确性的过程导向的验证奖励模型(PRM),来指导搜索过程。
这意味着,模型不仅需要生成最终的答案,还需要生成一个能够证明答案正确性的步骤序列。通过这种方式,验证模型可以针对每一步骤给出反馈,从而引导模型在生成过程中不断修正自己的路径找到最优解。
这种方法很适用于那些需要多步推理和验证的任务,例如,数学问题解决或者是逻辑推理题。在推理的过程中,模型会不断地评估不同的解决方案,并选择那些能够获得更高奖励分数的路径继续探索下去,直到找到最有可能正确的答案为止。
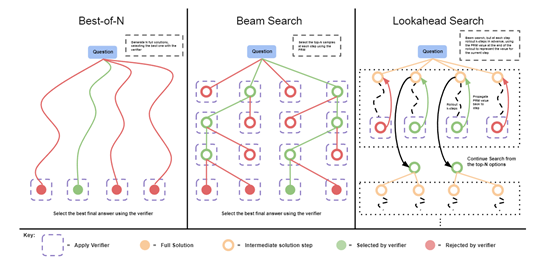
第二种自适应更新模型对响应的概率分布,则是在生成回答时,可以根据先前生成的内容来动态调整后续生成的内容。
例如,当模型接收到一个提示后,它并不会立即给出最终的回答,而是会先生成一系列可能的响应选项。然后,模型会根据这些选项的质量以及它们与原始提示的相关性来更新自己的概率分布,这样在下一轮生成时,模型就会倾向于选择那些更正确的选项。
通过多次迭代,模型能够逐渐优化其生成的回答,直到达到一个满意的程度。这种方法非常适合用于那些初始提示本身可能包含模糊信息的情况,或者当模型首次尝试生成的回答并不完全准确时,通过不断的修订来提高最终输出的质量。
这两种优化机制的使用,在很大程度上取决于问题本身的性质以及所使用的基线大模型的特点。例如,在处理相对简单的问题时,如果基础模型已经有足够的能力生成合理的初步答案,那么允许模型通过预测一系列的修订来迭代地改进其初始答案,可能会比同时生成多个独立的答案更为有效。
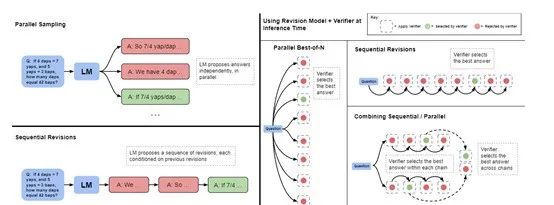
相反,对于那些需要考虑多种高级解决方案的问题,或者当模型面临的是特别困难的任务时,采用平行重新采样新答案或运用树状搜索配合过程导向的奖励模型,可能是更高效的方法。
所以,为了更高效的使用这两种优化方法,研究人员提出了“计算最优”的策略,可以根据每个提示的具体情况来选择最适合的测试时计算方法,从而最有效地利用额外的计算资源。
这种方法使得测试时计算的效率提高了超过4倍,相比于传统的最佳N选一的基线策略表现更为出色。
本文素材来源谷歌论文,如有侵权请联系删除
END




本篇文章来源于微信公众号: AIGC开放社区



