麻省理工创新模型:用2D视频扩散,生成 3D 视频
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
传统的3D 视频生成主要有两种方法,一种是通过2D 视频模型和静态 3D 场景模型的分类器指导来优化动态3D 视频场景表示,不过这种对算力的需求极大,生成一个 3D 视频需要数小时;
另一种是通过变形初始 3D 场景表示来实现,但需要严格的时间结构并且需调整复杂的参数。
为了解决这些难题,麻省理工、Databricks 马赛克科研所和康奈尔大学联合推出了创新模型Vid3D。该模型假设无需明确建模 3D 时间动态,通过生成2D视频的时序动态轮廓,然后独立地为视频中的每一帧生成3D表示,而无需考虑前后帧之间的时间连贯性。
论文地址:https://arxiv.org/abs/2406.11196

简单来说,就像在制作动画电影时,先绘制故事板,然后每个关键帧单独创建3D模型,而不是试图在三维空间中模拟整个场景的连续变化,这不仅节省算力复杂度也大幅度降低。
例如,我们想要生成一个猫在花园里玩耍的动态3D场景,Vid3D通过将生成任务分解为生成场景的2D时间动态和为每个时间步生成3D表示两个部分,极大降低了生成时间并简化了生成流程。
Vid3D先从一张参考图像开始,生成该场景的2D视频种子,也称为“时序播种”,旨在捕捉场景随时间变化的动态特征。再通过查询一个2D视频模型并输入参考图像,Vid3D能够获得动态渲染的对象,尽管此时只限于单一视角。这一步类似于在制作动画前先绘制出关键帧的故事板,为后续步骤提供了动态变化的基础框架。
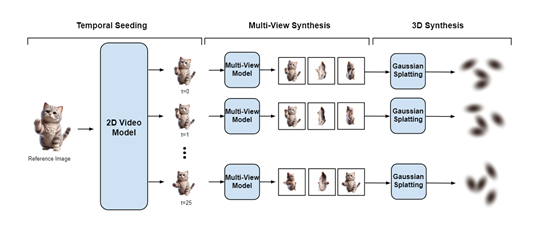
在多视图合成阶段,Vid3D针对种子视频中的每个时间步,独立生成多个视图来丰富场景的细节,并增强3D表示的准确性。
Vid3D使用了高斯溅射方法来生成3D场景的连续表示。高斯溅射是一种基于点云的方法,它通过在3D空间中散布大量的点,并为每个点分配一个高斯权重来表示场景的表面。这些点的集合,以及它们的高斯权重,共同定义了场景的3D形状和外观。

在Vid3D中,每个时间步的多视角视图被用来训练一个高斯溅射模型,该过程涉及到优化每个点的位置和权重,以便它们能够最好地表示从不同视角观察到的场景。这些训练好的高斯溅射模型序列定义了一个动态的3D视频,其中每个模型对应视频中的一个时间步。
最后在3D视频合成阶段,Vid3D将每个时间步的多视图集合转化为3D表示。这里使用的是Gaussian Splatting技术,这是一种能够将2D图像转换为3D几何结构的有效手段。通过训练一个Gaussian Splatting模型,Vid3D能够基于先前生成的多视图集合,构建出每个时间步的3D场景。
同时在种子视频的每一个时间步重复进行,最终形成了一个由一系列独立3D表示组成的动态3D视频。
为了评估Vid3D的性能,研究人员使用了最新评估基准。在评估过程中,为了测试每个 3D 视频的质量,从十个不同的均匀采样相机角度渲染 10 个 2D 视频,并使用 CLIP – I 分数作为定量评估指标。
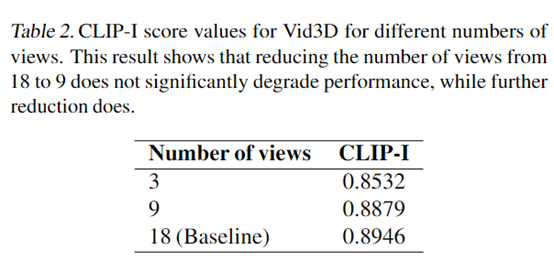
结果显示,Vid3D在生成动态 3D 视频场景方面非常出色,例如,Vid3D 的 CLIP – I 分数为0.8946高于Animate124 的 0.8544。此外,研究人员还对Vid3D中每个时间步生成的视图数量进行了消融实验。随着视图数量的减少,CLIP – I分数也开始降低,从18帧减少到9帧时,分数仅下降了0.0067,性能几乎没有变化。
本文素材来源Vid3D论文,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



