成本降低98%!OpenAI开发者大会4大新功能,处理量爆增50倍!
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
今天凌晨,OpenAI在美国旧金山召开了第二届开发者大会,发布了4大新的API功能。
分别包括实时API、视觉功能引入微调API、API提示缓存以及API模型蒸馏,大幅度简化模型的调用、微调、蒸馏等流程,实现“傻瓜式”高效开发。
Sam Altman表示,通过这些全新的API功能不仅能开发出强大且多元化的生成式AI功能、应用,同时将GPT-4、GPT-4o mini等模型的成本降低98%,同时处理token的数量暴涨50倍。

下面「AIGC开放社区」将为大家详细解读这4大API功能,对开发过程中有哪些重要帮助。
实时API
OpenAI在开发者大会上已经正式发布了实时API的公开测试版,允许所有付费开发者在他们的应用程序中构建低延迟、多模态的生成式AI功能。
实时API提供类似最近新开放的ChatGPT的高级语音模式,支持使用API中已经支持的6种预设声音进行自然的语音到语音对话。这也就是说,可以将ChatGPT的多模态语音功能集成在应用中了。
例如,可以开发一个外语口语训练应用,ChatGPT的语音模式可以帮助学员纠正他们的口语发音。
OpenAI还引入了聊天完成API中的音频输入和输出,以支持不需要实时API低延迟优势的用例。开发者可以将任何文本或音频输入传递给GPT-4o,模型将以他们选择的文本、音频或两者的组合进行响应。
此外,现在有了实时API,很快还有聊天完成API中的音频,开发者不再需要将多个模型拼接在一起来使用。你只需要使用一个API调用构建自然的对话体验。
大会现场
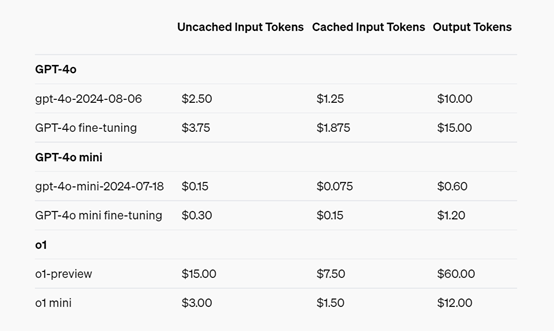
实时API使用文本和音频token价格:文本输入token的价格是每100万个5美元,输出token每100万个20美元。
音频输入的价格是每100万个100美元,输出是每100万个200美元。这相当于每分钟音频输入约0.06美元,每分钟音频输出约0.24美元,整体价格相当划算。
视觉功能引入微调API
自从OpenAI在GPT-4o上首次引入微调功能以来,已经有数十万开发者使用仅限文本的数据集定制了大模型,以提高特定任务的性能。但在许多特殊情况下,仅对文本进行模型微调并不能提供预期的性能提升。
所以,OpenAI在GPT-4o API上又引入了视觉微调功能,除了文本之外,还可以通过图像进行微调。开发者可以定制模型,使其具有更强的图像理解能力,从而实现增强的视觉搜索功能、改进自动驾驶车辆或智能城市的物体检测,以及更准确的医学图像分析等应用。

本次的视觉微调的过程与文本微调类似——开发者可以准备图像数据集,以遵循正确的格式,然后将该数据集上传到OpenAI的平台。可以使用至少100张图像来提高GPT-4o在视觉任务上的性能,并且随着文本和图像数据量的增加,性能会进一步提高。
例如,一家智能自动化平台Automat,构建桌面和Agent来处理文档并采取基于UI的操作,以自动化业务流程。通过视觉微调和屏幕截图数据集,Automat训练GPT-4o根据自然语言描述在屏幕上定位UI元素,将其RPA代理的成功率从16.60%提高到61.67%。
这与基础GPT-4o模型相比,性能提升了272%。此外,Automat仅使用200张非结构化保险文件图像训练GPT-4o,在信息提取任务上的F1分数提高了7%。

目前,GPT-4o的视觉微调功能每天免费提供100万token,有效期至10月31日。之后,GPT-4o微调训练将花费每100万token 25美元,推理将花费每100万输入token 3.75美元和每100万输出token15美元。
API提示缓存
许多开发者在构建生成式AI应用程序时,会在多个API调用中反复使用相同的上下文,例如,当修改代码库或与聊天机器人进行长时间的多轮对话时。
现在,OpenAI发布了了API提示缓存功能,允许开发者降低成本和延迟。通过重用最近看到的输入token,开发者可以享受50%的折扣和更快的提示处理时间。
新的API提示缓存会自动应用最新版本的GPT-4o、GPT-4o mini、o1-preview和o1-mini,以及这些模型的微调版本。
此外,对支持的模型的API调用将在提示长度超过1,024个token时自动受益于提示缓存。API会缓存提示中之前已计算过的最长前缀,从1,024个token开始,并以128个token为增量增加。

如果你重用具有相同前缀的提示,OpenAI将自动应用提示缓存折扣,无需你对API集成进行任何更改。缓存通常会在5到10分钟的不活动后清除,并始终会在缓存最后一次使用后一小时内移除。
API模型蒸馏
通常大模型蒸馏涉及使用更强大的模型的输出来微调更小、更经济的模型,使它们能够在特定任务上以更低的成本匹配高级模型的性能。
目前,模型蒸馏一直是一个多步骤、容易出错的过程,需要开发者手动协调多个操作,跨越不同的工具,从生成数据集到微调模型和衡量性能提升。由于蒸馏本质上是迭代的,开发者需要重复运行每一步,增加了大量复杂工作。
现在,OpenAI引入了一个全新的模型蒸馏服务,为开发者提供一个集成的工作流程,直接在OpenAI平台内管理整个蒸馏流程。
这个功能相当便利、高效,可以使开发者轻松使用o1-preview和GPT-4o等强大模型的输出,来微调和提高像GPT-4o mini这样更经济高效的模型的性能。
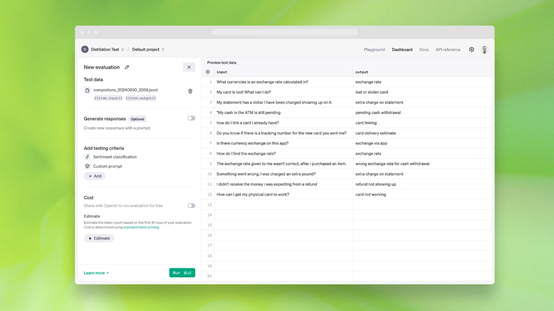
全新的API模型蒸馏包括:
存储完成:开发者现在可以通过自动捕获和存储GPT-4o、o1-preview等模型,通过API生成的输入-输出对,轻松地为蒸馏生成数据集。有了存储完成,你可以轻松地使用生产数据构建数据集来评估和微调模型。
评估集(测试版):开发者现在可以在OpenAI平台上创建和运行自定义评估,以衡量模型在特定任务上的性能。评估提供了一种集成的方式来衡量模型性能,而不是手动创建评估脚本和集成不同的日志工具。开发者可以使用存储完成中的数据或上传现有数据集来设置你的评估。评估也可以独立于微调使用,以定量评估模型性能。
微调:存储完成和评估完全集成到OpenAI现有的微调服务中。这意味着开发者可以使用存储完成创建的数据集进行微调工作,并使用评估在微调后的模型上运行评估,所有这些都在OpenAI的平台上完成。
以下是API模型蒸馏的示范:
首先,创建一个评估来衡量你想要蒸馏的模型的性能,我们就以GPT-4o mini为例。这个评估集将被用来持续测试蒸馏模型的性能,帮助你决定是否部署它。
接下来,使用存储完成创建一个蒸馏数据集,使用GPT-4o的输出来完成你想要微调GPT-4o mini的任务。你可以通过在聊天完成API中设置‘store:true’标志来自动存储这些输入-输出对,而不会产生任何延迟影响。这些存储的完成可以被审查、筛选和标记,以创建高质量的数据集进行微调和评估。

最后,使用这个数据集来微调GPT-4o mini。存储完成可以作为创建微调模型时的训练文件。一旦模型微调完成,你可以回到评估中去测试微调后的GPT-4o mini模型是否满足你的性能标准,与GPT-4o相比较。
需要注意的是,微调是一个迭代过程,如果初始结果不满意,你可能需要完善数据集,调整训练参数,或捕获模型表现不佳的更具体的例子,可以逐步提高蒸馏模型的性能,直到它能满足你的需求。
本文素材来源OpenAI,如有侵权请联系删除
END




本篇文章来源于微信公众号: AIGC开放社区



