Open AI开源新模型:采样效率提升100倍,颠覆图片生成!
添加书签

专注AIGC领域的专业社区,关注GPT-4、百度文心一言、华为盘古等大语言模型(LLM)的发展和应用落地,以及国内LLM的发展和市场研究,欢迎关注!
4月13日,Open AI的研究团队开源了全新生成模型Consistency Models(一致性模型),无需对抗训练即可快速生成高质量图片。(开源地址:https://github.com/openai/consistency_models)
Midjourney、DALL- E、Stable Diffusion等图片生成平台采用的是扩散模型,主要通过学习如何从完全由噪声构成的起始图像中逐渐减去噪声,使其一步步接近用户的文本提示,生成精美、高质量的图片。(论文地址:https://arxiv.org/abs/2303.01469)
但扩散模型有一个缺点,采样速度较慢,通常需要100—1000的评估步骤才能抽取一个不错的样本,需要消耗大量算力和时间。而Consistency Models可以使用1个步骤就能获得不错的样本,整体效率至少提升100倍同时也极大地降低了算力成本。
 Consistency Models效果展示,无需迭代瞬间出图
Consistency Models效果展示,无需迭代瞬间出图
简单来说,如果你不差钱有庞大的GPU算力集群1分钟轻松迭代1000个评估步骤,又想获得更佳的图片质量还是使用扩散模型体验最好。
这就像做刺绣一样,1000针的刺绣作品是强于1针的,毕竟慢工出细活。如果你的算力有限但又想获得差不多的体验,Consistency Models是一个不错的选择。诚然,随着Consistency Models技术的不断迭代其性能将更加卓越。
此外,在Consistency Models加持下,使得像图片生成这样的AI应用可以直接在手机上运行成为现实。例如,在聊天应用里内置该模型可以实时生成用户想要的图片、表情包等,这提升了AI应用的场景化落地范围。
为什么说Consistency models具有颠覆性
从Consistency models的论文来看,虽然扩散模型在图像、音频和视频生成方面取得了重大突破,扩散模型成功的关键是迭代采样过程。该过程逐渐从随机噪声向量中去除噪声。
这种迭代优化过程重复评估扩散模型,允许计算与样本质量的权衡。通过使用额外的计算进行更多迭代,小型模型可以展开成更大的计算图并生成更高质量的样本。但它们依赖于迭代生成过程,导致采样速度缓慢并限制了在应用中的潜力

为了克服这些限制,Open AI提出了Consistency models模型,这是一个新的生成模型家族,无需对抗训练即可实现高样本质量。核心是支持1步生成,同时仍然允许迭代生成以进行零样本数据编辑以及样本质量和计算之间的权衡。

Consistency models可以在蒸馏模式或隔离模式下进行训练。在前一种情况下,一致性模型将预训练扩散模型的知识提取到单步采样器中,显着提高了其他蒸馏方法的样本质量。
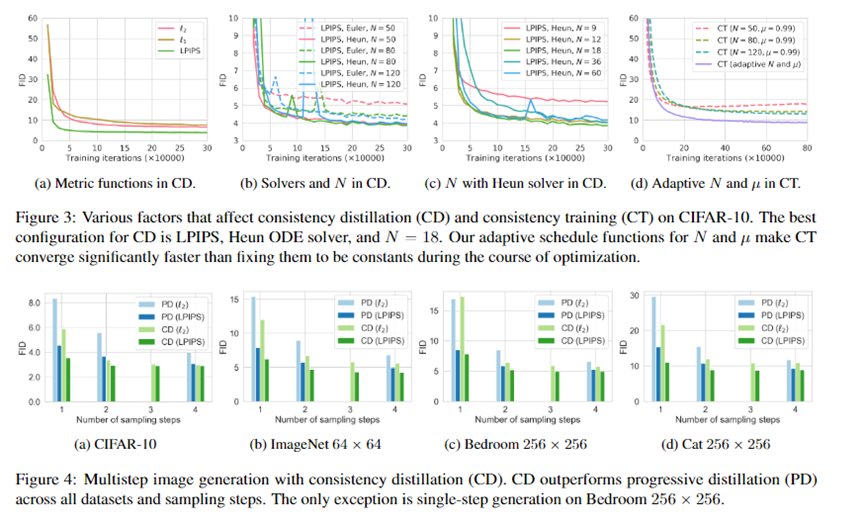
Consistency models还支持零镜头数据编辑,如图像修复、着色和超分辨率,而无需对这些任务进行明确的训练。
同时Consistency models可以作为提取预训练扩散模型的一种方式进行训练,也可以作为独立的生成模型进行训练。通过广泛的实验,已证明它们在一步生成和几步生成中优于现有的扩散模型蒸馏技术。

目前,Consistency Models只展示了在图片领域的应用。但很多人预测,随着该技术的成熟会向音频、视频等领域扩展,甚至会与ChatGPT相融合降低其成本提升响应效率。
值得一提的是,宋飏(Yang Song)是该开源项目的主要负责人之一。宋飏本科毕业于清华大学物理系数理基础科学专业,并获得了斯坦福大学计算机博士学位,师从Stefano Ermon教授。目前,宋飏担任OpenAI研究科学家。2024年1月,将作为助理教授加入美国加州理工学院。

本文素材来源Open AI,如有侵权请联系删除
END
加入AIGC开放社区交流群
添加微信:13331022201 ,备注“职位信息&名字”
管理员审核后加入讨论群



