类ChatGPT开源模型,允许商业化!Dolly 2.0震撼发布!
添加书签

专注AIGC领域的专业社区,关注GPT-4、百度文心一言、华为盘古等大语言模型(LLM)的发展和应用落地,以及国内LLM的发展和市场研究,欢迎关注!
全球知名云计算服务商Databricks在官网发布了拥有120亿参数,类ChatGPT开源模型Dolly 2.0。(开源地址:https://huggingface.co/databricks/dolly-v2-12b)
目前,已开源的类ChatGPT模型Alpaca、Guanaco、LuoTuo、Vicuna、Koala、BAIZE、Latin Phoenix等,都有一个致命缺点——无法商业化。因为这些项目都是基于LLaMA开发的,其规定只能用于学术研究不能商业化。并且多数训练数据是从Open AI的API获取,被禁止用于打造竞品。
Dolly 2.0是基于EleutherAI pythia模型开发,已获得了商业化许可。这对于那些无法承担昂贵的ChatGPT API企业、个人开发者来说是一个大福利。并且Databricks是一家成立了10多年的云数据AI管理公司,在12个国家设有办事处,其AI产品在功能迭代、创新方面非常高效稳定。
值得一提的是,Dolly 2.0不仅开源了代码,就连15,000个纯人工生成的原始问答数据训练集也开源了,同样可以用于商业化。Databricks认为,他们是全球首家开源原始大模型训练数据集的厂商。(数据集开源地址:https://github.com/databrickslabs/dolly/tree/master/data)

5,000名员工帮助Dolly 2.0打造原始训练数据集
其实20天前,Databricks就发布了Dolly1.0,仅用了30美元的成本就训练出了类似ChatGPT的大语言模型。无数的开发者问了同样的问题,可以商业化吗?答案是不可以。
Dolly 2.0产品演示
这是因为Dolly1.0使用了OpenAI API的数据集,进行了关键步骤和响应对数据集上的训练。如果厂商使用了OpenAI API获取的数据进行核心模型训练,全部禁止商业化。
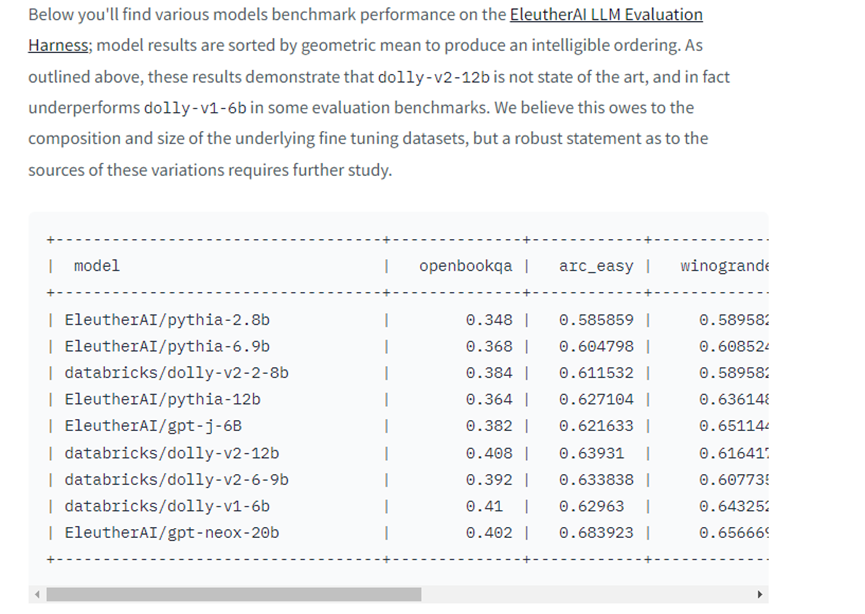
从Open AI的论文来看,原始InstructGPT模型是在一个包含 13,000 个指令遵循行为演示的数据集上训练的。也就是说,如果能原创13,000个问答,就可以避开Open AI顺利实现商业化。
Databricks受此启发,调集内部5,000名员工开始编写脑洞、常规、创意写作、分类、文本摘要、特定场景等几乎涵盖所有领域的,15,000个高质量原创人工生成的问答提示,用于专门训练Dolly 2.0。

事实上,原创15,000个问答并且丝毫不能与ChatGPT生成的数据集重复是相当困难的,如果出现重复整个训练集都会遭到污染,不能用于商业化。
为了激励员工,Databricks在内部举办了一个原创问答数据比赛,前20名将获得大奖。并且Databricks还规定了原创问答的范围,例如,总结维基百科的知识,原创诗歌/情书,写一段脑洞大开的演讲等。
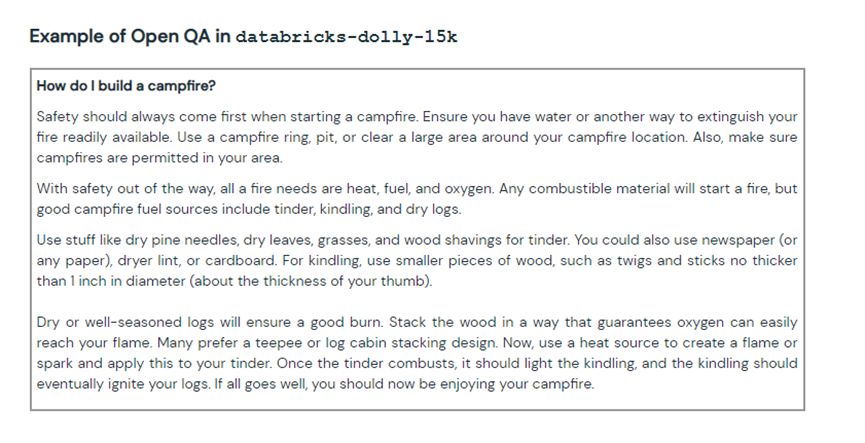
起初,Databricks认为能收到10,000个原创问答都很困难,实际上员工对这个活动充分了兴趣,最终收货了超过15,000个高质量数据集。经过高质量的数据集训练Dolly 2.0的问答表现几乎完美复刻了ChatGPT。
Databricks表示,由于训练集有限,Dolly 2.0在复杂语法提示、开发代码、复杂逻辑运算、文笔模仿等方面还有很大的进步空间。但Databricks会加快对Dolly 2.0的功能迭代,使其变得更加强大、高效。
关于Databricks
Databricks创立于2013年总部位于美国旧金山,在12个国家设有办事处。主要提供云数据管理服务,企业客户超过7,000家,典型客户包括:微软、亚马逊、Tableau、Booz Allen Hamilton等世界知名企业。
本文素材来源Databricks,如有侵权请联系删除
END
加入AIGC开放社区交流群
添加微信:13331022201 ,备注“职位信息&名字”
管理员审核后加入讨论群



