AutoGPT以及生成式代理,是大模型应用的未来吗?
添加书签

专注AIGC领域的专业社区,关注GPT-4、百度文心一言、华为盘古等大语言模型(LLM)的发展和应用落地,以及国内LLM的发展和市场研究,欢迎关注!
针对在《ChatGPT的问题分析和解决思路》一文中谈到几个问题,例如无法联网、缺乏上下文知识、事实缺失等,我们来看看有什么解决方案。
第一种思路:“缺什么补什么”
这个应用范式可以理解为“GPT+X”,X代表虽然GPT缺失,但传统已有的应用。例如:
-
为了解决ChatGPT无法连接互联网的问题,那么就给它加上传统的搜索引擎,例如ChatGPT+Bing,Bard+Google,文心一言+百度等;
-
由于传输Token和上下文受限,就按照垂直领域给它来个性化定制,例如PDF+GPT(ChatPDF),Blog+GPT(Glasp),Web+GPT(Glarity)等;
-
ChatGPT没有长期记忆,聊过一次就忘,那就加个外部存储,例如向量数据库(Milvus,Pinecone),图数据库看(Data Graph)等;
本质上是在提升GPT“聊”的能力,让它聊的更准确,更长久,更有价值,希望利用人与机器聊天这个基本交互模式,完成更多的应用处理。
相反,另个应用范式可以理解为“X+GPT”,X代表已有的应用,然后再添加AI能力,让原能力变得更强大。对于已经存在的传统应用,在语言处理等AI能力上也有欠缺,便可以借助GPT来提升能力,辅助原有工作,提升工作效率,增加额外价值。例如办公领域的Office Copliot,笔记和绘图领域的Notion.AI和Miro.AI,编程IDE的Copilot X等。
第二种解决方案:类似传统工作流任务式的集成
不管是“GPT+X”还是“X+GPT”,都难以解决不能通过简单的聊天接口所完成的复杂任务,这些才是企业应用的难点。
一种方式是通过传统的工作流引擎,也包括RPA或者API Platform来集成ChatGPT和已有的应用或接口,例如Uipath/Automation Anywhere + ChatGPT,ChatGPT Plugin + Zapier等,这种模式虽然类似于“X+GPT”,但由于X本身自身的强大集成能力,可以发挥更大作用。
这个应用范式可以理解为“任务分解器+GPT”。
另一种方式是通过GPT作为语言引擎,自身具备的语言粘合效应。为此,目前业界研发了两个典型的运行和集成框架:
(一)微软的HuggingGPT+Jarvis
JARVIS 由微软发布,作为 AI 控制器系统运行。可以同时控制多个 AI 模型以完成多模态多任务。HuggingGPT 是一个旨在解决 AI 任务的系统,它使用语言作为接口,将大型语言模型 (LLM) 与各种 AI 模型连接起来。主要思想是使用 LLM 作为控制器来管理 AI 模型,并利用来自 Hugging Face 等社区的模型来解决不同的用户请求。它首先应用LLM来理解用户请求并将其分解成小任务,然后将这些任务分配给不同的功能模型来完成,最后再次使用LLM将结果汇总为最终输出。
工作流程:
-
任务规划:LLM 了解用户的请求,并根据需要将其分解为子任务。
-
模型选择:LLM根据每个子任务的描述选择最合适的专家模型。
-
任务执行:HuggingGPT 使用选定的模型执行任务,整合它们的结果以提供全面的响应。
-
生成回复:LLM整合所有模型的计算结果,为用户生成回答。

(二)基于开源框架LongChain的BabyAGI
BabyAGI 是task-driven autonomous agent的简化版本, 由@yoheinakajima平台开发。Task-driven autonomous agent任务驱动的自主代理是一个智能系统,它利用 OpenAI 的 GPT-4 语言模型、Pinecone 矢量搜索和 LangChain 框架来执行跨不同领域的广泛任务。主要有四个模块,包括完成任务、根据完成的结果生成新任务、实时确定任务的优先级、历史任务和结果存储,所有这些都在约束和上下文中进行。工作流程:
-
用户给出目标要求和第一个任务,也是当前要执行的任务
-
将任务放入一个安全代理,安全代理有助于确保系统生成的输入和输出符合道德和安全准则,降低意外后果的风险
-
安全代理返回安全合规的结果
-
利用ChatGPT的能力作为任务生成器Task Generator,生成新的任务New Task,放入任务清单Tasklist
-
依据规则或者外部要求,安排任务优先级 Task Prioritization
按照优先级顺序生成当前要执行的任务Current Task
二者有些相似,Jarvis像是个任务分解器,而LangChain更像是任务排队执行的集成器。但它们都需要解决任务执行中的准确度和错误率的问题,不同任务的错误率的偏差和叠加,都会给结果带来灾难性的后果,后续我将再做专题分析。 这种应用模式可理解为“GPT+任务管理器+任务执行器”,GPT不再只是提供简单交互的Chat工具,而成为了任务判断,任务决策,任务路由,任务检查的AI“路由器”。 以上两种方案,还算容易理解。那么就有人思考,“为什么不让GPT自己来解决问题”,而不再依赖人工干预,这就有了……. 
第三种解决思路——“AI自治”。
说到AI自治,不得不介绍近期大火的开源项目Auto-GPT。Auto-GPT 是一个基于 GPT-4 语言模型构建的实验性自治应用程序。它旨在通过提供各种功能来展示 GPT-4 的潜力,例如用于搜索和信息收集的互联网访问、长期和短期记忆管理、使用 GPT-4 实例生成文本、访问流行的网站和平台, 以及使用 GPT-3.5 进行文件存储和汇总。 而这些人工智能“代理人”会自行自动运行并为您完成任务, 这允许它递归地调试、开发和自我改进。

Auto-GPT刚刚面世几天,Github上就已经获得了7万颗星,对比多年前已推出的百度飞桨引擎,目前也才2万颗星。网上目前已经流传着AutoGPT的各种传说和用例,在此就不再赘述了,我重点分析一下它面临的问题和障碍,以及未来的发展前景。
-
高昂的成本
由于Auto-GPT的任务是通过一连串的想法完成的,每一步都需要调用昂贵的GPT-4模型,该模型通常最大化令牌,以提供更好的推理和提示。
GPT-4令牌并不便宜,初步估算GPT-4的每步执行的总成本约0.288美元,Auto-GPT平均需要50个步骤来完成一个小任务,为此完成一项任务的成本约是14.4美元。
-
开发和生产未分离
因为Auto-GPT分解和产生任务的过程和任务的执行过程混合在了一起,也就意味着每次运行它都需要14.4美元。事实上,任务分解更像是个流程的设计和定义,属于流程设计的范畴
Auto-GPT没有办法将操作链上的任务“序列化”作为可重用的功能。因此,用户每次想要解决问题时,都必须从头开始开发这个任务链。
也许以上2个问题还容易解决,但Auto-GPT的循环卡死,才是制约它发展的关键。
-
陷入自我循环的泥潭
许多用户报告说,Auto-GPT经常陷入循环,使其无法解决实际问题。这揭示了Auto-GPT即使在处理了一整晚的思想链后仍然停留在循环中的情况,而无法完成用户要求的目标。
为什么Auto-GPT会卡在这些循环中?
因为Auto-GPT可以成功达成目标任务取决于两个因素:
一是单个步骤的能力,即该编程语言中可用的函数范围,Auto-GPT提供了有限的一些细化功能,如搜索网络、管理内存、与文件交互、执行代码和生成图像的功能,这组受限的功能自然缩小了Auto-GPT可有效执行的任务范围。
二是GPT分解任务和完成任务的能力,即GPT如何将任务分解为预定义的编程函数。尽管GPT-4比GPT-3.5有显著改进,但其问题分解不足、无法识别情况以及缺乏适应性和学习等,进一步限制了Auto-GPT的问题解决能力。
这就好像,GPT是个装修的包工头,通过口头语言交代给下属的工人,而这些工人的技能单一,包工头的分工能力又不足,使得二者无法协调统一,从而导致各方扯皮,工期延误。分而治之的方法虽然,还有赖于“分”的能力和“治”的能力都能达到用户的要求。
生成式代理是希望之光吗?
所以Auto-GPT希望通过允许生成式代理Agent来委派任务。一是引入异步代理。结合异步模式,代理并发运行,便不会相互阻塞,即采用异步方法来同时管理多个并发任务。二是实现代理Agent之间的相互沟通,让Agent进行沟通和协作,一起工作来解决复杂的问题。类似于编程中的IPC概念,多个线程/进程可以共享信息和资源来实现共同目标。
在近日,斯坦福大学和谷歌发布了一篇《生成式代理:人类行为的交互式仿真》(Generative Agents: Interactive Simulacra of Human Behavior)的论文,他们扩展了一个大型的语言模型,以存储代理使用自然语言的经验的完整记录,将这些记忆随着时间的推移合成为更高层次的思考,并动态地检索它们以规划行为。同事,将生成式代理实例化,以填充一个受《模拟人生》启发的互动沙盒环境,在那里,终端用户可以使用自然语言与一个由25个代理组成的小镇进行互动。通过观察,这些生成代理产生了可信的个人和突发的社会行为。
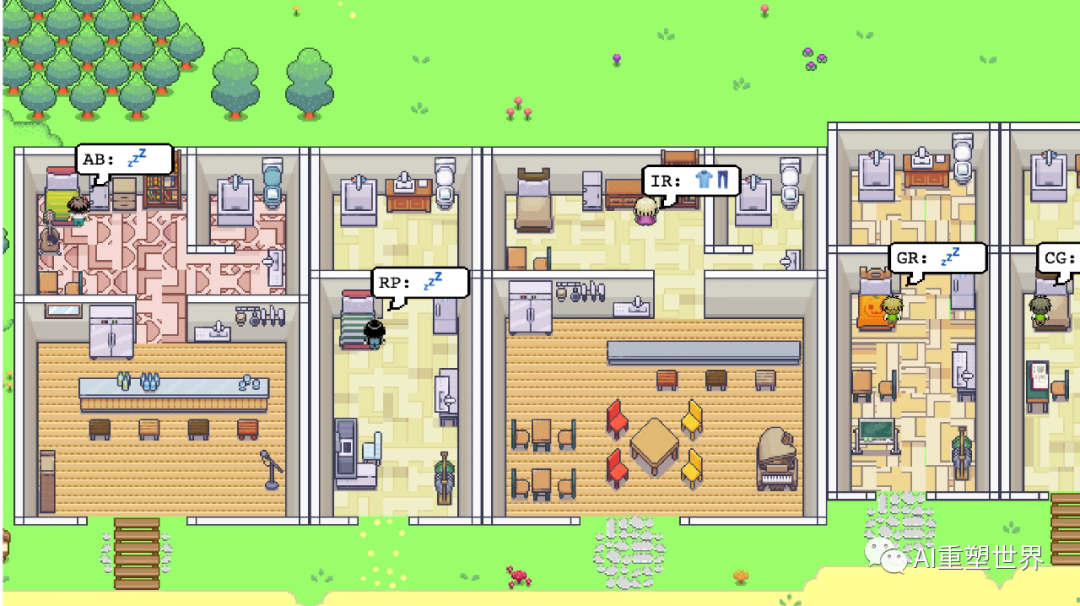
希望通过生成式代理来完全解决AI自治的问题,我想答案是悲观的。原因是在一个自封闭系统中,通过不断的任务分解和解决,再加上任务链上的错误叠加,只会导致情况变得更加复杂,反而不利于达成任务目标,也就是常说的“墒增”。熵增定律揭示了所有生命和非生命的演化规律:任何一个系统,只要满足封闭系统,而且无外力维持,它就会趋于混乱和无序。
一个组织也好,社会也好,有效解决问题的方法是“熵减”,也就是及时建立好封闭系统的秩序,让其按章执行,这也是大多数企业的治理之道。再精巧的模拟人生,也只能用于社会观察,而无益于实现目标。虽然Auto-GPT正在努力尝试,但在我看来,却是在错误的方向上狂奔。
END

加入AIGC开放社区交流群
添加微信:13331022201 ,备注“职位信息&名字”
管理员审核后加入讨论群



