类ChatGPT多模态开源模型,支持识别图片,性能媲美GPT-4!
添加书签

专注AIGC领域的专业社区,关注GPT-4、百度文心一言、华为盘古等大语言模型(LLM)的发展和应用落地,以及国内LLM的发展和市场研究,欢迎关注!
4月18日,阿卜杜拉国王科技大学的研究团队开源了类ChatGPT模型MiniGPT-4。除了生成文本之外,具备识别图片的多模态功能。这与微软前不久开源的Visual ChatGPT非常相似,也是一个“眼睛+嘴巴”的组合模型。
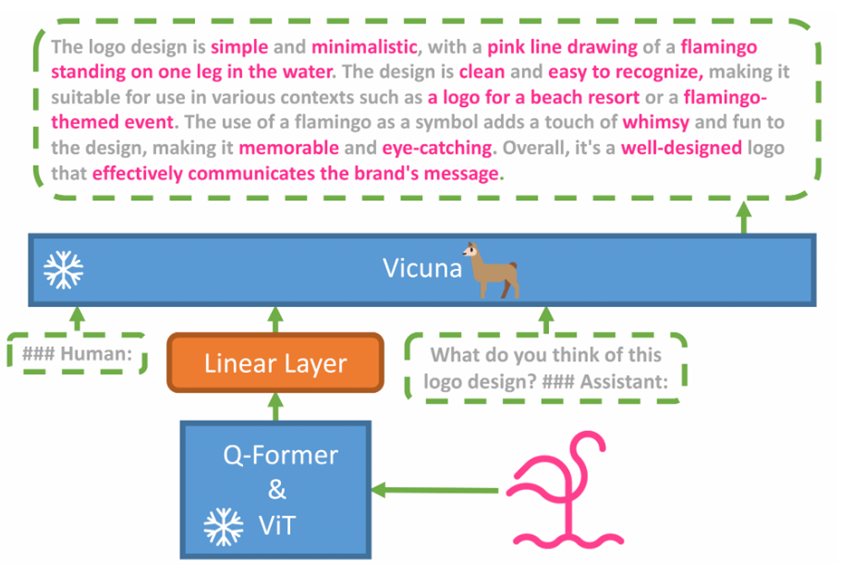
据悉,MiniGPT-4 由一个带有预训练 ViT 和 Q-Former 的视觉编码器、一个线性投影层以及高级 Vicuna 大型语言模型组成。其中,Vicuna是一个130亿参数的类ChatGPT开源模型,性能方面媲美GPT-4。资源消耗非常低,可以在单个 NVIDIA 3090/4080/V100(16GB) GPU 上运行。
ViT和Q-Former视觉编码器,可以根据图片和提示生成文本,这也充当了MiniGPT-4的“眼睛”,具备看图说话的功能。
开源地址:https://github.com/Vision-CAIR/MiniGPT-4
在线试用:https://687d119023cd37e5fb.gradio.live/
论文:https://github.com/Vision-CAIR/MiniGPT-4/blob/main/MiniGPT_4.pdf
Open AI发布的GPT-4大语言模型再一次拉升了ChatGPT的能力,其强大的看图说话能力进一步扩大的ChatGPT的应用范围。由于GPT-4没有开源并且API需要申请审核才能使用,这让很多企业、开发者只能干羡慕。
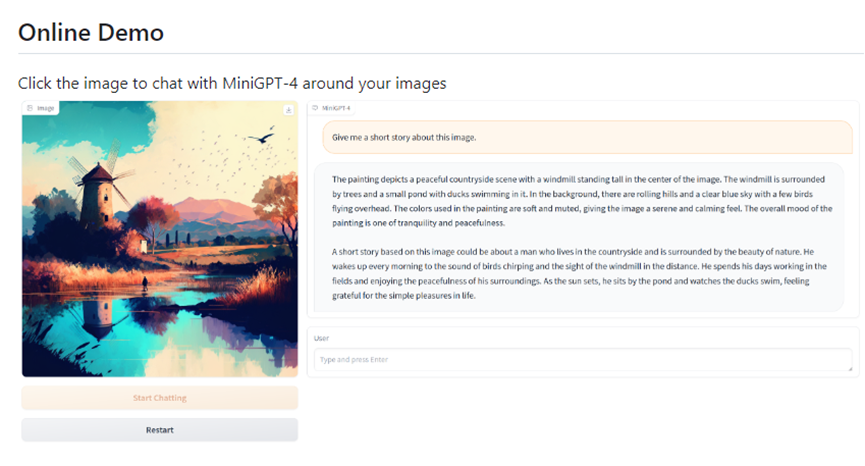
MiniGPT-4为了探索GPT-4功能,通过将类ChatGPT模型与视觉模型相结合使用,从而实现类似GPT-4的看图说话功能。例如,上传一张田园照片,然后问“能帮我讲一个关于这张照片的小故事吗?”。AI机器人很快就能为用户创作一段故事。
其实,MiniGPT-4这种组合方法并不新鲜,微软之前开源的Visual ChatGPT就采用过。他们将类ChatGPT模型与多个 SOTA 视觉基础模型连接,实现在对话系统中理解和生成图片。目前,该开源项目在github已突破3万颗星非常受欢迎(开源地址:https://github.com/microsoft/visual-chatgpt)
但想以最佳效果实现模型组合也并不容易,因为整个映射、对齐过程非常复杂、繁琐,例如,有大量重复、难以理解的语句和图片,微调效果不佳整个产品的性能也将大打折扣。
模型训练方面,MiniGPT-4一共采用了两个阶段进行训练。第一阶段预训练,该模型使用来自Laion和CC数据集的图像文本对进行训练,以对齐视觉和语言模型。训练完成后,视觉特征被映射,可以被语言模型理解。
第二阶段微调,使用独立创建的小型高质量图文对数据集,并将其转换为对话格式以进一步对齐MiniGPT-4。在对齐之后,MiniGPT-4 能够连贯地理解用户意图,并根据图片生成特定文本内容。总体而言,在两个阶段完美训练之后,MiniGPT-4达到了可以媲美GPT-4的能力。
功能方面,根据MiniGPT-4展示的示例来看,在识别图片方面非常优秀,可以根据用户的图片和提问自动生成相对应的文本内容。例如,根据一张鸟叼着灯的图片,让机器人生成一则广告。

此外,MiniGPT-4支持多轮连续对话,可以根据特定图像为用户生成更有深度的内容。
值得一提的是,本次开发的MiniGPT-4是一个阿卜杜拉国王科技大学华人博士团队完成,包括,朱德尧、Chen Jun、沈晓倩、LiXiang和Mohamed Elhoseiny教授。


本文素材来源MiniGPT-4,如有侵权请联系删除
END





