智源研究院:要建设大模型时代的Linux
添加书签

专注AIGC领域的专业社区,关注GPT-4、百度文心一言、华为盘古等大语言模型(LLM)的发展和应用落地,以及国内LLM的发展和市场研究,欢迎关注!
萧箫 整理自 AIGC峰会
量子位 | 公众号 QbitAI
ChatGPT引爆了大模型,也彻底将大模型相关的AI产业生态带到了新的阶段——
大模型的“涌现能力”,让AI真正展现出了商业化潜力。
然而,也是在这一阶段,想要跟上大模型浪潮的企业,也势必要面对大模型应用所面对的诸多挑战:
在面对不同行业的不同需求时,什么参数量的大模型才是正确的选择;当前大模型无法解决的幻觉,不同领域又要如何应对……
作为一家长期致力于大模型研发的人工智能研究机构,智源研究院如何看待这一阶段大模型的挑战,又会如何应对这波AIGC+大模型浪潮?
智源研究院副院长兼总工程师林咏华认为:
当下我们看到的更多是现象级AI应用,譬如AIGC文生图、类ChatGPT多任务生成模型等,但更重要的是冰山之下的技术栈。

为了完整体现林咏华的思考,在不改变原意的基础上,量子位对演讲内容进行了编辑整理,希望能给你带来更多启发。
中国 AIGC 产业峰会是由量子位主办的行业峰会,近 20 位产业代表与会讨论。线下参与观众 600+,线上收看观众近 300 万,得到了包括 CCTV2、BTV 等在内的数十家媒体的广泛报道关注。
话题要点
-
大模型已经从语言模型上升到认知模型。
-
当下我们看到的更多是现象级AI应用,譬如AIGC文生图、类ChatGPT多任务生成模型等,但更重要的是冰山之下的技术栈。
-
大模型不仅要追求创新性,还要直视未来10年在产业落地过程中形成的新挑战,包括参数量的选择、训练数据等。
-
过去10年,AI快速发展,开源开放的作用不容忽视。
-
当前模型测评任务太简单,需要用更难、更复杂的评测来拉动大模型的发展。
以下为林咏华演讲全文:
大模型面临哪些新挑战?
今天我带来的题目是《Why Large Model, Why Open Source》。
AI浪潮在此前数十年三起三落,去年“大模型+AIGC”的发力,又激发AI浪潮从谷底冲至巅峰。
过去几个月,媒体对ChatGPT的解读已经很充分,而底层大模型是这一切的基座。随着GPT-4的发布,ChatGPT构建在预训练模型之上的对话式生成模型能力得到一个很大的跃进,就不在这里赘述。
大模型的确出现了强大的泛化能力和涌现能力。它能通过人类不同专业领域的考试,例如在美国大学预修课程AP考试中,GPT-4在15门考试获得9门A、4门B,完全达到美国大学本科生的水平;在十多种不同领域的专业考试中已超过人类平均水平。
可见,大模型已经从语言模型上升到认知模型。为什么它可以产生这种能力?
2022年,谷歌曾发表了一篇讨论大模型涌现能力的文章《Emergent Abilities of Large Language Models》,发现当模型参数量达到百亿甚至以上时,在多种任务的few shot或者zero shot上展现了突出的涌现能力。

这也导致了“大炼大模型”现象的产生,伴随有两个重要趋势:一是模型参数越来越大,从1亿参数到万亿参数的模型已经出现;另一个是模型正在从单模态变成多模态。
这意味着大模型不仅要追求创新性,还要直视未来10年在产业落地过程中形成的新挑战:
-
第一,参数量的选择。到底多大的参数量可以支持我们的应用需求?是要追求千亿模型、还是百亿模型就够?
-
第二,海量的训练数据。具体需要有多少训练数据才足够“喂饱”一个百亿或者千亿模型,又有多少信息可以传递到下游任务?
-
第三,评估标准。当模型从单模态走向多模态、从语言模型走向认知模型,我们该怎么评测?
-
第四,大模型持续学习和定点纠错能力。如何让超大规模的模型用较低成本继续学习新的知识、吸纳新的信息?当发现模型输出有错时,如何对基础模型做到定点纠错?
-
最后,很重要的一点是大模型的训练效率、推理效率。
AIGC的成功,需要大模型技术全栈的创新突破。
当下我们看到的是现象级AI应用,譬如AIGC文生图、类ChatGPT多任务生成模型等,但更重要的是冰山之下的技术栈。
一方面,是各类重要的预训练模型,包括语言预训练模型、视觉通用模型、跨模态模型等;另一方面,对这些模型进行预训练的方法,包括数据集、处理数据集的工具和大模型评测方法都至关重要。
此外,也离不开最下面的AI大模型系统技术,包括对训练框架做并行优化、做平台调度优化、甚至用不同架构的AI加速芯片支持大模型训练和推理,都需要投入。

智源如何应对大模型浪潮?
智源研究院专注发展冰山之下的大模型技术栈。
我们打造并开源了包括语言、视觉、图文跨模态、文生图在内的多个预训练大模型,开放了中文等多个语言的上百个数据集及数据工具,并联合多个研究队伍、多家厂商一起,共同打造了AI基础大模型的评测系统。
为了对AI大模型进行系统深入的研究,我们自建了九鼎AI大模型智算平台,包括英伟达和多种国产AI芯片集群,以针对大模型训练进行多任务优化。
过去10年,AI快速发展,开源开放的作用不容忽视,我们也不断站在前人的肩膀上继续前行。
作为中立、非营利研发机构,智源一直在大模型技术发展中保持开源开放的态度,围绕大模型从底向上技术体系,把所有重要技术都通过开源与产业共享。
FlagOpen正是我们和多家企业、高校共同倾力打造的大模型开源技术体系,可以类比为大模型领域的Linux。
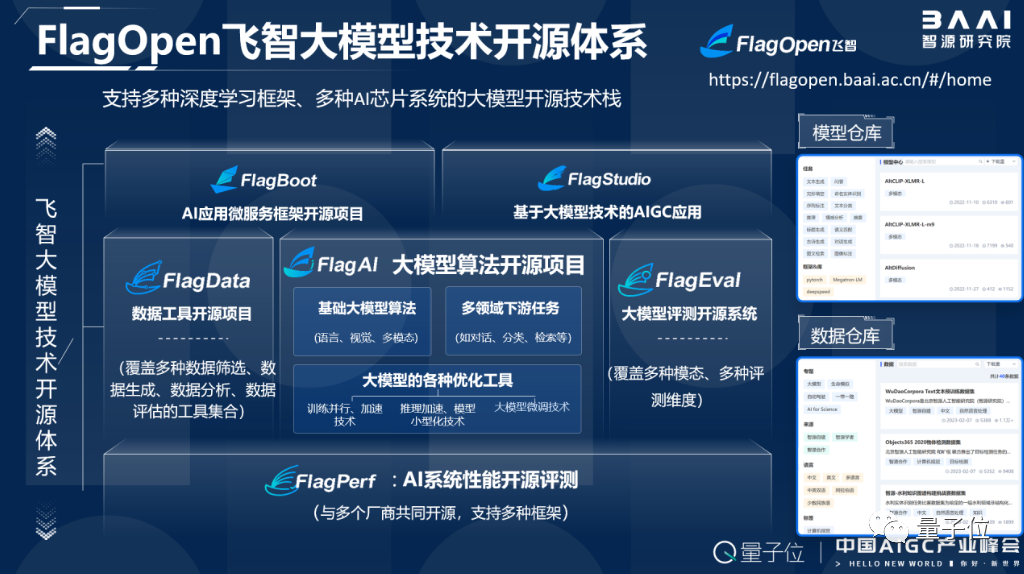
其中,最核心的是FlagAI大模型算法、模型及工具一站式开源项目,包括智源自有的“悟道”系列大模型、以及各种全球流行的大模型新算法。
我们通过代码整合和结构优化,为不同的大模型算法搭建统一的pipeline,并与众多主流的并行训练优化技术进行整合,以提升大模型算法的可用性、降低大模型开发者的门槛。
大模型预训练中的数据很重要,因此我们也开源了一整套FlagData数据工具开源项目。FlagData中的数据清洗、过滤、压缩还有分析等能力,可以帮助开发者高效搭建流程,促进产业发展。
此外,FlagEval是面向基础大模型的评测开源项目,而FlagPerf则是针对各种AI芯片的评测开源项目,当前我们也正联合多个厂商一起,共同进行AI系统尤其是大模型的开源评测。
在构建大模型开源技术体系的过程中,智源致力于携手多个厂商团队,打造支持不同深度学习框架和异构芯片的软件体系。
智源开源了哪些大模型?
这里给大家举一些例子,介绍智源过去几个月已经开源的部分重要大模型。
首先是文图表征模型。
随着GPT-4发布,多模态已经成为大模型的下一个制高点,而多模态模型十分依赖文图跨模态预训练基础模型的性能。
一直以来,多语言文图基础模型的发展受制于训练数据,即多语言文图训练数据量太少。例如,在最流行的LAION-5B文图数据集中,英文的文图对数据达到95%以上,而中文等语言数据太少了。
智源的AltCLIP多语言文图表征模型,就针对多语言做了一系列算法创新,使得只用很少的数据就能构建出多语言的文图预训练大模型,并在所有语言上的性能达到SOTA。
目前,AltCLIP-m9已经支持包括英文、中文在内的九种语言,近期还将发布更多语言的版本,希望帮助更多国家用本土语言实现文图方面的跨模态应用。
去年,我们基于自研的AItCLIP-m9,开源了全球第一个多语言文图生成大模型AItDiffusion-m9。
用不同的语言来描述,它生成的图会有些不同,例如用俄语输入一个女孩的描述,大家可以看到女孩的头像是俄罗斯风格的,而用阿拉伯语描述一篮水果,生成的花篮就是阿拉伯风格的。

不同的语言会生成带有不同民族或国家特色的画面,这也正是多语言文图预训练模型的重要能力。
智源在视觉方面也实现了重要进展,推出了EVA通用视觉编码模型。
它在开放域可以针对很多非常困难的长尾数据进行高质量识别。
普通视觉模型,一般只能做到几十种物体的高质量识别和分割,但在开放领域如在我们的生活世界里,肯定不止几十种物体,而这也是自动驾驶等领域需要考虑的问题。
EVA通用视觉编码模型,能够在超过1000个不同类别的长尾实例分割数据集LVIS上,大幅突破现有业界最优的性能。

另一项重要工作,是我们在今年开源的通用视觉解码器Painter。Painter有两大突破:
一方面,它真正意义上实现了一个统一多种下游视觉任务的视觉模型,包括分类、目标识别、分割、关键点检测等,在实现复杂视觉任务上方便了不少;
另一方面,它首创了在视觉领域的“In-context learning”,打破了当前依赖文本语言进行提示学习的单一性,未来将有可能为我们带来更多AI的可能性。

大模型需要怎样的评测技术?
随着大模型技术的快速迭代,相应的评测技术变得尤为重要。
在未来人工智能大模型时代,大多数企业不会自己从头训练一个模型,而会选用别人的模型,因此评测一定会成为推动大模型发展的关键。
给大家举一个文图跨模态大模型的例子,这里有三种业界公认的评测任务,分别为低、中、高难度。

低难度的cross-modal retrival任务在Flickr30k评测集上面已经做到90分,基本超过人类,中难度的zero-shot图片分类接近70分,也接近人类水平。
但在高难度的视觉-语言组合理解任务上,目前业界最好的这批跨模态语言模型也只能拿到10分上下的水平,距离人类的80分、90分相差很远。
我们认为,需要用更难、更复杂的评测来去拉动大模型的发展,而不是一直停留在低中难度。
因此,智源在FlagEval大模型评测开源项目中,发布了当前最为完整的文图多模态大模型评测项目,涵盖12种语言7大任务,包括刚才的低、中、高三种难度。
随着大模型技术发展,模型评测任务正面临更大挑战。
从过去的传统AI模型评测集,到2022年斯坦福提出的HELM(一个以理解能力评测为主的、针对语言大模型的整体系统化评测集),再到语言生成能力、认知能力、乃至人类思维能力等模型智能水平评测,如果持续推进下去,整个评测系统一定会发生翻天覆地的变化。
今年,智源牵头和30多家企业、高校共同打造大模型技术基座,并做面向大模型的支撑平台和评测技术。这里包括数据集及数据平台、基础大模型技术评估体系及评测系统,还有开源开放的算法系统。
我们希望能尽快开放一套适合大模型评测的平台,并邀请更多团队来参与评测、或是参与评测系统的构建。
智源作为人工智能领域的新型研发机构,自2020年确定大模型研究战略方向以来,不仅深耕大模型研究,在过去两年推出全球领先的悟道大模型系列,而且也更加关注技术栈的开源开放,目标是协同更多开发者、企业和高校,一起打造适合国内甚至全球的大模型技术基座。
目前,智源已经聚集了一批全球技术领先的大模型研究团队,希望更多人工智能领域的有志之士加入我们,从底层的技术栈到先进的大模型,我们共同创造卓越。
同时,智源也坚持开放创新,希望通过跟整个产业的开源共创,共同打造大模型的全栈技术,谢谢大家!
本文来源量子位,如有侵权请联系删除
END
「AIGC开放社区」ChatGPT对话机器人大合集,扫描二维码免费使用





