类ChatGPT开源厂商Together,获1.4亿元融资
添加书签

专注AIGC领域的专业社区,关注GPT-4、百度文心一言、华为盘古等大语言模型(LLM)的发展和应用落地,以及国内LLM的发展和市场研究,欢迎关注!
5月16日,大语言模型开源厂商Together宣布获得2000万美元(约1.4亿元)种子轮融资,本次由Lux Capital 领投,Factory、SV Angel、First Round Capital、PayPal联合创始人Scott Banister 等跟投。
Together是一家「AIGC开放社区」报道过的类ChatGPT开源厂商,其产品RedPajama-INCITE具备与ChatGPT一样的问答功能。但在几乎同等的性能上算力消耗更低,普通笔记本就能跑30亿参数模型,甚至5年前发布的RTX 2070显卡也没问题。
目前,市面上类ChatGPT开源平台多如牛毛,几乎每天都有新品推出,例如,Alpaca、Guanaco、LuoTuo、Vicuna、Koala等。为何Together能获得巨额种子轮融资?这是因为Together手握两张王牌。
第一,其开源平台可以商业化,目前市面上多数开源平台都是基于LLaMA开发而成,LLaMA明文规定只能用于学术研究不允许商业化。
第二,Together曾开源1.2万亿token训练数据集(约5T),这在开源界非常罕见。也就是说中小型企业、个人开发者可以无需大规模数据训练就能直接使用其开源产品,进一步扩大了商业化落地空间。

RedPajama-INCITE开源产品介绍
RedPajama-INCITE(以下简称RedPajama)是在5月5日才开源的类ChatGPT产品,主要提供30亿、70亿两种参数,特点是功能强大算力消耗低,可在笔记本、普通显卡运行,适用于中小企业和个人开发者。
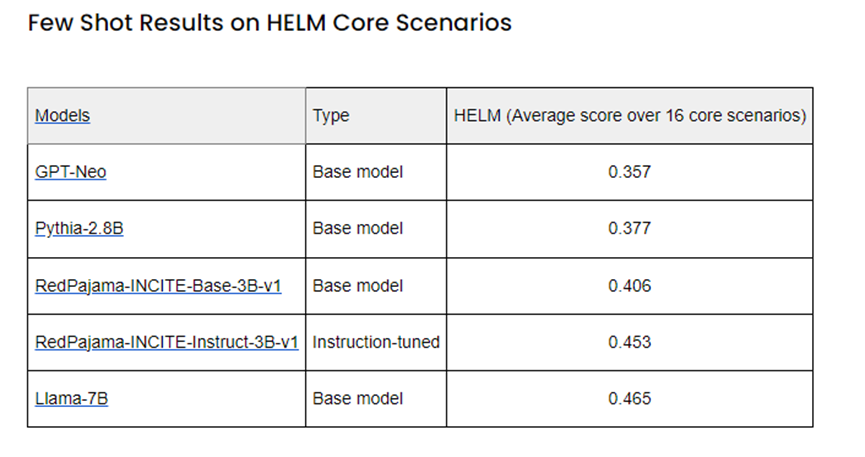
30亿参数:主要包括基础款、聊天款和指令调优三个版本。在8000亿token数据集上进行训练,在HELM和Eleuther的测试中比同类的GPT-Neo、Pythia-2.8B更优秀。自动生成的文本丝滑流畅,可以加入拟人化情感。
30亿参数开源地址:https://huggingface.co/togethercomputer/RedPajama-INCITE-Base-3B-v1
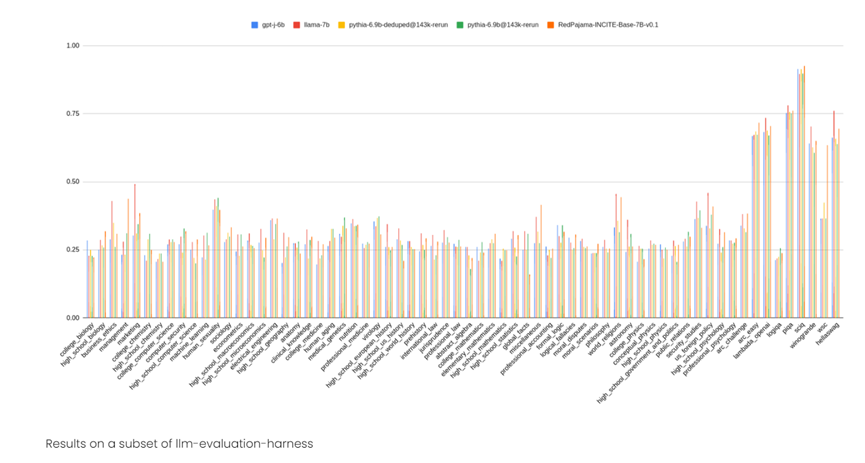
70亿参数:也是在8000亿token数据集上进行训练,RedPajama希望扩大至1万亿。主要包括基础款、聊天款和指令调优三个版本。其中,指令调优版本的测试结果非常棒,甚至高于LLama-7B版本。
70亿参数开源地址:https://huggingface.co/togethercomputer/RedPajama-INCITE-Chat-7B-v0.1
RedPajama曾开源1.2万亿token训练数据集
今年4月17日,RedPajama曾宣布开源1.2万亿token数据集,帮助开发者训练类ChatGPT大语言模型。(开源地址:https://huggingface.co/datasets/togethercomputer/RedPajama-Data-1T)
RedPajama完美复制了LLaMA模型上的1.2万亿训练数据集,按照其论文的数据模式从维基百科、GitHub、普通抓取、C4、图书、ArXiv、Stack Exchange抓取了1.2万亿训练数据,并进行了数据优化、过滤。
其中,普通抓取渠道获取了8780亿数据,并通过多个质量过滤器进行过滤,包括选择类似维基百科页面的线性分类器。C4获取1750亿,基于标准 C4 数据集。GitHub获取590亿,按许可证和质量过滤;图书获取260亿,包括开放书籍的语料库,并根据内容相似性进行去重。
ArXiv获取280亿,去除了样板文件的科学文章。维基百科获取240亿,基于子集数据删除了样板内容。StackExchange获取200亿,基于子集数据删除了样板内容。目前,Together正在打造RedPajama V2,这是一个包含2万亿token的训练数据集。

Together表示,非常感谢蒙特利尔大学的AAI CERC实验室,斯坦福基础模型研究中心,Ontocord.ai,Meta AI,EleutherAI,OLCF等学术机构和开源社区的鼎力支持。如果没有他们贡献核心训练代码、架构、数据,根本不可能推出RedPajama。
本文素材来源Together官网,如有侵权请联系删除
END
「AIGC开放社区」ChatGPT对话机器人大合集,扫描二维码免费使用





