国家超级计算天津中心发布,「天河天元大模型」
添加书签
专注AIGC领域的专业社区,关注GPT-4、百度文心一言、华为盘古等大语言模型(LLM)的发展和应用落地,以及国内LLM的发展和市场研究,欢迎关注!
5月19日,在第七届世界智能大会上,国家超级计算天津中心正式发布打造“天河E级智能计算开放创新平台”,研发训练“天河天元大模型”。
算力成为人工智能发展的核心驱动
大模型发端于自然语言处理领域,以谷歌的BERT、OpenAI的GPT和百度文心大模型为代表,参数规模逐步提升至千亿、万亿,用于训练的数据量级也显著提升,带来了模型能力的提高,同时这也代表了算力消耗的指数级上升。
 (国家超级计算天津中心供图)
(国家超级计算天津中心供图)
而超级计算可以说是算力中的战斗机,单体最强大算力的存在,由于超级计算作为一个系统工程、超级大脑,每一代超级计算都要完成数据交换能力升级、系统级软件升级等才能实现整机系统的突破,因此超级计算研制能力成为体现国家信息技术创新能力,特别是算力发展的重要象征。
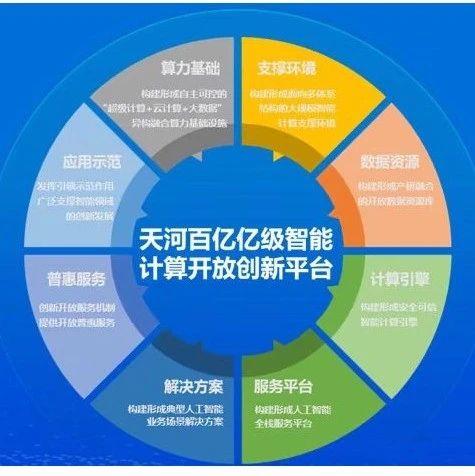
天河超级计算机,从千亿亿次到亿亿次、十亿亿次,再到现在百亿亿次,不断挑战世界算力速度极限。
“在天河新一代超级计算系统中,我们设计实现了柔性体系架构,支持带来世界领先的双精度、单精度、半精度融合计算输出能力。”国家超级计算天津中心首席科学家孟祥飞介绍,天河在完成传统的高精度科学工程计算之外,构建基于自主E级算力体系架构的智能计算引擎,建设人工智能大规模训练与应用系统支撑环境。天河E级智能计算开放创新平台将带来突破百亿亿次的跨模态的超级计算算力,支撑传统的科学工程计算,并服务智能混合计算,打造全方位的算力赋能创新和数字经济高质量发展载体。
中文数据集支撑的天河天元大模型
数据是AI发展的基石,是产业智能化发展中最宝贵的资源。海量的数据为人工智能自监督学习带来巨大助力。
众所周知,中文大语言模型的数据集非常稀缺。孟祥飞介绍,天津超算中心搜集整理了网页数据、各种开源训练数据、中文小说数据、古文数据、百科数据、新闻数据以及专业领域的中医、医药、问诊、法律等多种数据集,训练数据集总token数达到350B,训练打造了自己的中文语言大模型——天河天元大模型。
同时大模型还在持续训练和完善中,并在此基础上启动深度训练面向医疗、工业、法律等领域的专业模型。
据介绍,未来大模型将带动新的产业和服务应用范式,在深度学习平台的支撑下将成为产业智能化基座。在人工智能统一底座上融合专家知识图谱,即可打造面向跨场景或行业服务的“元能力引擎”。该模式将进一步驱动各行各业的生产能力、生产效率从“量变到质变”,实现跨越式发展。
以超级算力与生成式AI打造行业专家
“行业大模型就是在基础大模型上,进一步融合行业数据、知识以及专家经验,提升大模型对行业应用的适配性。”孟祥飞表示,预训练大模型增强了人工智能的通用性、泛化性,基于大模型通过零样本或小样本精调,就可实现在多种任务上的较好效果。大模型“预训练+精调”等模式带来了新的标准化AI研发范式,实现AI模型在更统一、简单的方式下规模化生产。
“这将会带来一场以通用人工智能为驱动力的‘AI革命’。”孟祥飞说。
将大模型作为产业智能化升级基座,用专业数据集,打造更贴合行业领域的智能化高水平“专家”。同时为行业赋能,推动行业升级,提升领域创新效率、行业生产效率,是人工智能驱动新一轮科技革命和产业变革的巨大力量。
未来,以生成式AI为基座的产业链将成为智能化升级过程中可大规模复用的基础设施。在大模型通用性、泛化性以及降低人工智能应用门槛的优势推动下,人工智能也将会加快落地,形成新的机遇。
孟祥飞表示,希望能通过这样一个发布的契机,跟大家分享超级算力发展与生成式AI创新突破,更希望为未来创造更多协同发展的可能。让“天河天元大模型”赋能百业,赋能中国高质量发展。
本文来源中国高新网,如有侵权请联系删除
END
「AIGC开放社区」ChatGPT对话机器人大合集,扫描二维码免费使用





