专注AIGC领域的专业社区,关注GPT-4、百度文心一言、华为盘古等大语言模型(LLM)的发展和应用落地,以及国内LLM的发展和市场研究,欢迎关注!

韩国顶尖公立大学KAIST(韩国科学技术院)根据LLaMA模型,推出了具备自我反馈、迭代能力的类ChatGPT开源模型SelFee(70亿、130亿两种参数)。
SelFee的自我反馈、迭代能力相当新奇,无需借助外力可自我评估并生成。无论是在开源界、还是各大科技公司推出的产品中都很罕见。「AIGC开放社区」根据在线demo体验了一下,例如,中国有哪些著名景点?SelFee首个回答,北京、上海、广州等地有故宫、颐和园、明珠塔等景点(内容很丰富、流畅)。
随后系统会对第一个答案进行评价:回答的内容很完整,并列出了具体的城市和景点,但没有更具体的描述,例如,交通方式、门票、节日活动信息等,整体答案只能给8分,并不是很满意。
接着,SelFee会按照评价标准再次生成更详细的答案。系统照样会对答案进行评价,如果达不到标准,会让SelFee继续生成答案,至少修订3次内容,并且是一次性生成。
总体来说,这种实时自我反馈、迭代能力的大语言模型非常新颖,内容生成效率很高。非常擅长创意文本,逻辑、衔接、拟人化等方面非常优秀几乎和ChatGPT无差别,想体验别样类ChatGPT对话功能的可以试试。
开源地址:https://github.com/kaistAI/SelFee
在线体验:https://kaistai.github.io/SelFee/demo
 SelFee生成答案展示
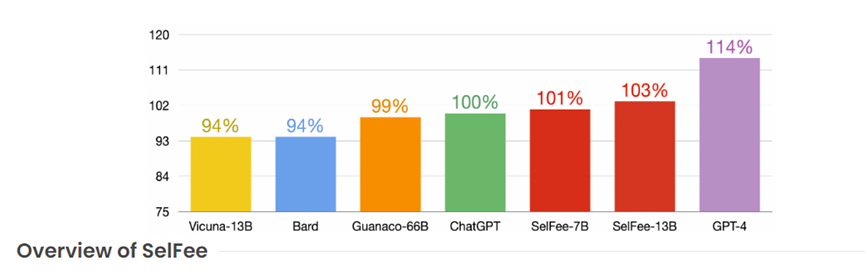
SelFee的70亿参数和130亿参数在性能评估方面,皆优于LLaMA、Alpaca、Vicuna、Guanaco、Bard等大语言模型产品,与 ChatGPT 的能力基本持平,仅低于GPT-4模型。
SelFee的自我反馈学习模式,无需进行文档检索或外部反馈可自我迭代。其技术原理是,在出现问题Q时, SelFee不仅会生成初始答案A0,还会生成反馈序列 F0。
SelFee生成答案展示
SelFee的70亿参数和130亿参数在性能评估方面,皆优于LLaMA、Alpaca、Vicuna、Guanaco、Bard等大语言模型产品,与 ChatGPT 的能力基本持平,仅低于GPT-4模型。
SelFee的自我反馈学习模式,无需进行文档检索或外部反馈可自我迭代。其技术原理是,在出现问题Q时, SelFee不仅会生成初始答案A0,还会生成反馈序列 F0。
 SelFee自我反馈、迭代展示
模型通过分析生成的反馈内容F0,确定是否需要修改。如果需要修改,模型会根据F0 生成修改后的答案 A1,还会生成A1的反馈内容F1,至少修订3次。
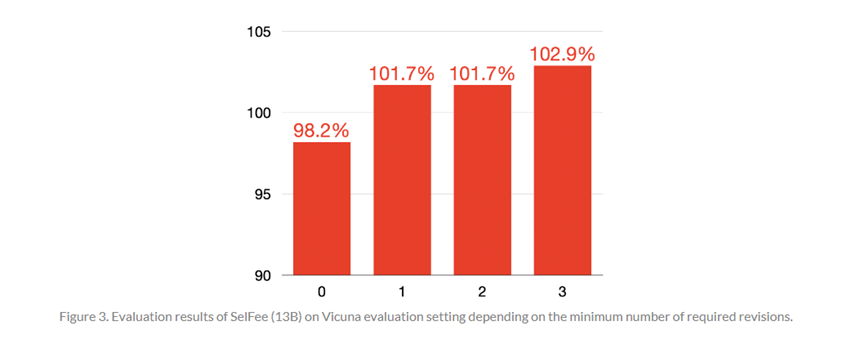
在推理的过程中,SelFee发现,生成至少3次修订结果的70亿模型,明显优于没有修订的130亿模型。这说明,增加语言模型的推理计算,比简单增加模型参数的大小更有用。
SelFee从ShareGPT、Alpaca、Math、Code 和 Flan Collection收集了指令数据,形成了一个包含178K个训练实例的数据集。同时使用 OpenAI API进行了数据扩充。扩充流程包括以下3个步骤:
1,SelFee从多个来源收集了一系列提问指令,并将它们输入到 ChatGPT 中,以生成相应的答案。
2,通过再次询问 ChatGPT 获得对生成答案的反馈,并要求其评估是否需要对初始答案进行修改。
3,如果认为有必要修改,让 ChatGPT 根据自行生成的反馈内容进行修改答案。反复重复这个过程,直到模型确定不需要修改为止。
对于数据扩充,SelFee使用了来自五个不同来源的数据集。包括 Stanford Alpaca、数学数、代码、Flan和 ShareGPT五种数据集。
总体来说,SelFee非常擅长写创意长文本几乎与ChatGPT所展示的性能无差别,尤其是经过修订后的内容。
但在数学、推理、编码方面略差一些,这主要是因为基础模型架构和训练数据集的原因。
KAIST创立于1971年,是韩国大田广域市的一所公立研究型大学。KAIST在韩国有很高的评价和业界认可度,是环太平洋大学联盟、东亚研究型大学协会、全球大学校长论坛、亚太管理学院联合会成员。
KAIST 在全球大学排名中的表现一直非常出色,尤其在工程和科技领域。此外,KAIST 的毕业生在就业市场上具有很高的竞争力,许多毕业生进入知名企业、研究机构或继续深造。
SelFee自我反馈、迭代展示
模型通过分析生成的反馈内容F0,确定是否需要修改。如果需要修改,模型会根据F0 生成修改后的答案 A1,还会生成A1的反馈内容F1,至少修订3次。
在推理的过程中,SelFee发现,生成至少3次修订结果的70亿模型,明显优于没有修订的130亿模型。这说明,增加语言模型的推理计算,比简单增加模型参数的大小更有用。
SelFee从ShareGPT、Alpaca、Math、Code 和 Flan Collection收集了指令数据,形成了一个包含178K个训练实例的数据集。同时使用 OpenAI API进行了数据扩充。扩充流程包括以下3个步骤:
1,SelFee从多个来源收集了一系列提问指令,并将它们输入到 ChatGPT 中,以生成相应的答案。
2,通过再次询问 ChatGPT 获得对生成答案的反馈,并要求其评估是否需要对初始答案进行修改。
3,如果认为有必要修改,让 ChatGPT 根据自行生成的反馈内容进行修改答案。反复重复这个过程,直到模型确定不需要修改为止。
对于数据扩充,SelFee使用了来自五个不同来源的数据集。包括 Stanford Alpaca、数学数、代码、Flan和 ShareGPT五种数据集。
总体来说,SelFee非常擅长写创意长文本几乎与ChatGPT所展示的性能无差别,尤其是经过修订后的内容。
但在数学、推理、编码方面略差一些,这主要是因为基础模型架构和训练数据集的原因。
KAIST创立于1971年,是韩国大田广域市的一所公立研究型大学。KAIST在韩国有很高的评价和业界认可度,是环太平洋大学联盟、东亚研究型大学协会、全球大学校长论坛、亚太管理学院联合会成员。
KAIST 在全球大学排名中的表现一直非常出色,尤其在工程和科技领域。此外,KAIST 的毕业生在就业市场上具有很高的竞争力,许多毕业生进入知名企业、研究机构或继续深造。
本文素材来源KAIST官网,如有侵权请联系删除
END