专注AIGC领域的专业社区,关注OpenAI、百度文心一言等大语言模型(LLM)的发展和应用落地,关注LLM的基准评测和市场研究,欢迎关注!
视频在当今社交媒体和互联网文化中扮演着愈发重要的角色,抖音,快手,B 站等已经成为数以亿计用户的热门平台。用户围绕视频分享自己的生活点滴、创意作品、有趣瞬间等内容,与他人互动和交流。
近期,大语言模型展现出了令人瞩目的能力。我们能否给大模型装上 “眼睛” 和 “耳朵”,让它能够理解视频,陪着用户互动呢?
从这个问题出发,阿里达摩院的研究人员提出了 Video-LLaMA,一个具有综合视听能力大模型。Video-LLaMA 能够感知和理解视频中的视频和音频信号, 并能理解用户输入的指令,完成一系列基于音视频的复杂任务,例如音 / 视频描述,写作,问答等。目前论文,代码,交互 demo 都已开放。另外,在 Video-LLaMA 的项目主页中,该研究团队还提供了中文版本的模型,让中文用户的体验更丝滑。

Video-LLaMA 采用了模块化设计原则,把视频中的视觉和音频模态信息映射到到大语言模型的输入空间中,以实现跨模态指令跟随的能力。与之前侧重于静态图像理解的大模型研究(MiNIGPT4,LLaVA)不同,Video-LLaMA 面临着视频理解中的两个挑战:捕捉视觉中的动态场景变化和整合视听信号。
为了捕捉视频中的动态场景变化,Video-LLaMA 引入了一个可插拔的视觉语言分支。该分支首先使用 BLIP-2 中预训练好的图片编码器得到每一帧图像的单独特征,再与对应的帧位置嵌入结合后,所有图像特征被送入 Video Q-Former,Video Q-Former 将聚合帧级别的图像表示并且生成定长的综合视频表征。最后采用一个线性层将视频表征对齐到大语言模型的 embedding 空间。

至于视频中的声音信号,Video-LLaMA 使用音频 – 语言分支进行处理。首先从原始视频中均匀采样多个时长两秒的音频片段,并将每个片段转换为 128 维的梅尔频谱图。然后,采用强大的 ImageBind 作为音频编码器,单独提取每个声音片段的特征。在添加可学习的位置嵌入后,Audio Q-Former 将片段特征进行整体聚合,并生成固定长度的音频特征。与视觉语言分支类似,最后采用线性层将音频表征对齐到大语言模型的 embedding 空间。
为了减少训练成本,Video-LLaMA 冻结了预训练好的图片 / 音频编码器,只更新了视觉和音频分支中的以下参数:Video/Audio Q-Former,位置编码层以及线性层(如图 1 所示)。
为了学习视觉和文本的对齐关系,作者们首先利用大规模的视频 – 文本数据集 (WebVid-2M) 和图像 – 文本数据集(CC-595K)对视觉分支进行预训练。之后,作者们利用来自 MiniGPT-4,LLaVA 的图像指令数据集和来自 Video-Chat 的视频指令数据集来微调,从而达到更好的跨模态指令跟随能力。
至于音频 – 文本对齐关系的学习,由于缺乏大规模高质量的音频 – 文本数据,作者们采用了一种变通策略来达到这一目标。首先,音频 – 语言分支中可学习参数的目标可以理解为将音频编码器的输出与 LLM 的嵌入空间对齐。而音频编码器 ImageBind 具有非常强的多模态对齐能力,它能将不同模态的嵌入对齐到一个共同的空间中。因此,作者们使用视觉 – 文本数据来训练音频 – 语言分支,将 ImageBind 的公共嵌入空间对齐到 LLM 的文本嵌入空间,从而实现音频模态到 LLM 文本嵌入空间对齐。通过这种巧妙的方式,Video-LLaMA 能在推理过程中展现出理解音频的能力,即使从未接受过音频数据的训练。
作者展示了 Video-LLaMA 基于视频 / 音频 / 图像的对话的一些例子。
(1)下面两个例子展示了 Video-LLaMA 的视听综合感知能力,例子中的会话围绕有声视频展开。在例子二中,画面上仅仅显示了这个演奏家,但是声音中是观众的欢呼声和掌声,如果模型只能接受视觉信号,将无法推测到观众的积极响应,音频中并没有乐器的声音,但画面中出现了萨克斯,如果模型仅能接受听觉信号,也将无法得知演奏家演奏了萨克斯。


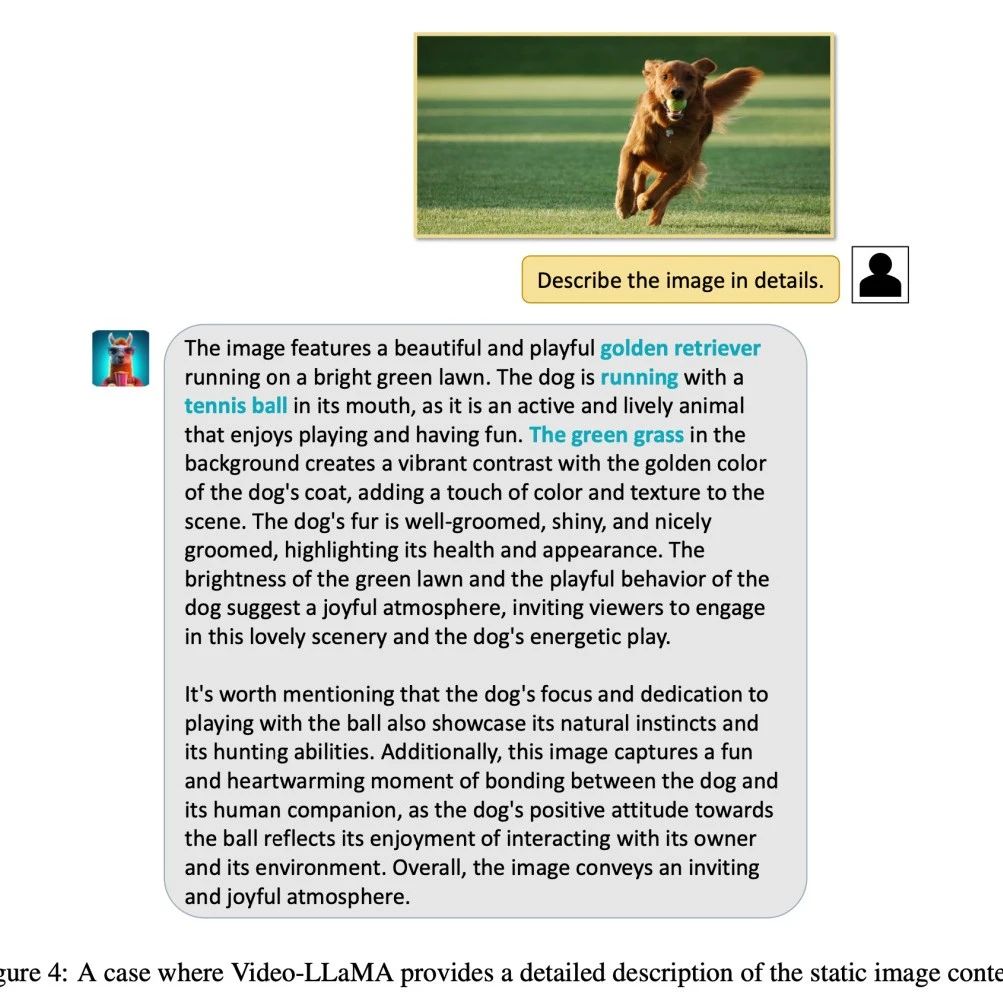
(2)Video-LLaMA 对于静态图像也有较强的感知理解能力,可以完成图片描述,问答等任务。
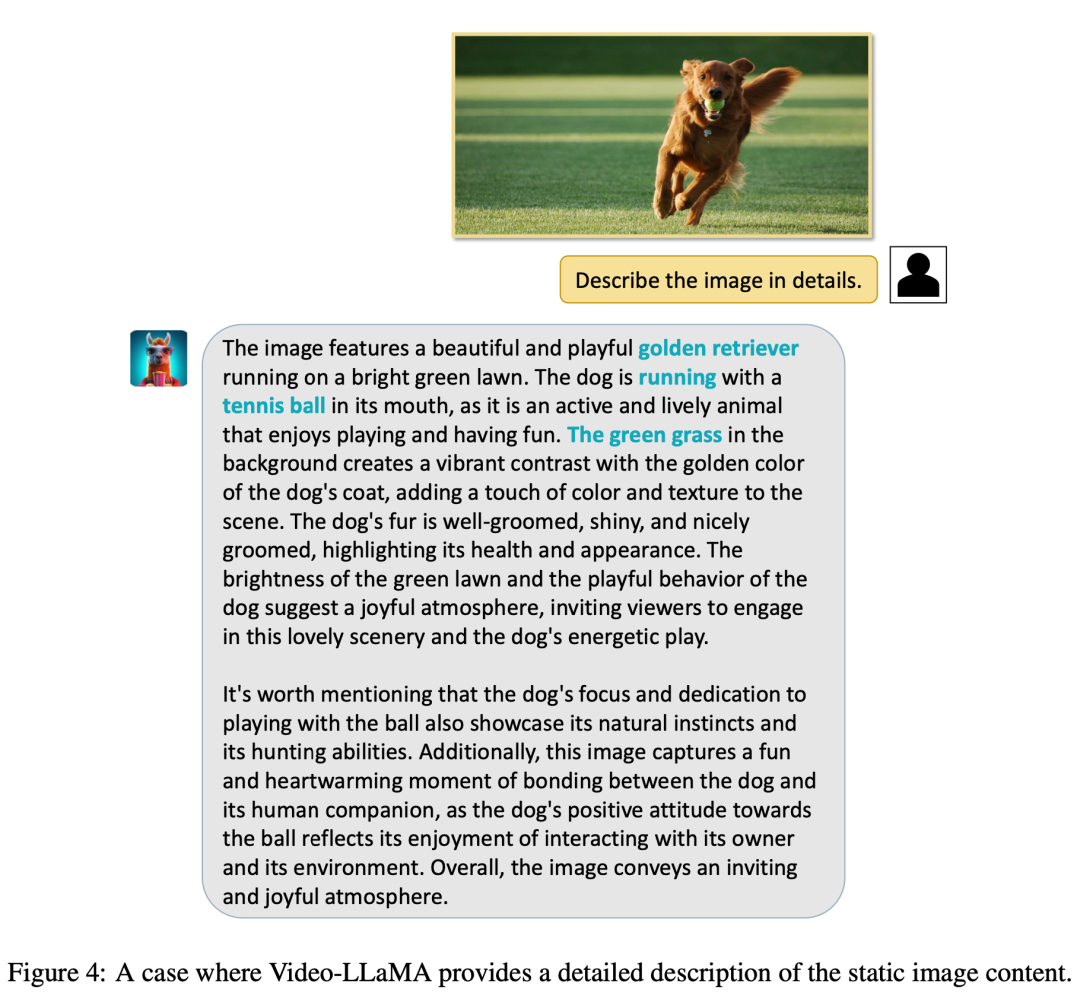

(3)令人惊奇的是,Video-LLaMA 能成功识别著名的地标和人物,并能进行常识性问答。比如下面 VIdeo-LLaMA 就成功识别出了白宫,并介绍了白宫的情况。又比如输入一张龙妈和囧雪的剧照(经典影视剧《权利的游戏》中角色),VIdeo-LLaMA 不仅能够成功识别,而且能说出他们剪不断理还乱的关系。

(4)针对于视频的动态事件,Video-llama 也能很好捕捉,例如嘘声的动作,小船行驶的方向。


目前,音频视频理解依旧是一个非常复杂,尚未有成熟解决方案的研究问题,Video-LLaMA 虽然表现出了令人印象深刻的能力,作者也提到了其存在一些局限性。
(1)有限的感知能力:Video-LLaMA 的视觉听觉能力仍然较为初级,对复杂的视觉声音信息依然难以辨认。其中一部分原因是数据集的质量和规模还不够好。该研究团队正在积极构建高质量的音频 – 视频 – 文本对齐数据集,以增强模型的感知能力。
(2)难以处理长视频的:长视频 (如电影和电视节目) 包含大量的信息,对模型的推理能力和计算资源都较高。
(3)语言模型固有的幻觉问题,在 Video-LLaMA 中依然存在。
总的来说,Video-LLaMA 作为一个具有综合视听能力的大模型,在音频视频理解领域取得了令人印象深刻的效果。随着研究者的不断攻坚,以上挑战也将逐个被克服,使得音视频理解模型具有广泛的实用价值。
本文来源机器之心,如有侵权请联系删除
END