ChatGPT遭遇史上最难问题,差点“宕机”
添加书签

今天,一条#问ChatGPT中国足球如何赢得世界杯冠军#的话题冲上微博热搜榜,阅读量达到6617万。ChatGPT的“宕机”视频,受到了不少网友的围观和激烈讨论。
有博友表示,第一次见到ChatGPT回答问题考虑这么久,之前让它回答“先有鸡还是先有蛋”都没考虑这么久。还有表示,一个问题能干烧人工智能CPU也是无解了… …
沉默几十秒后,ChatGPT给出了一句简单又刺痛人心的话——中国足球夺冠世界杯是一个很有挑战性的目标。这就有意思了,ChatGPT居然懂职场规则,万事不把话说死,既不说能夺冠,也不说不能夺冠,而是很有挑战性。
该问题发布在某音时同样引起了不小的关注,获得了13万赞和1.3万评论。看来ChatGPT不仅能写论文、代码、文章,整活儿也是一把好手。
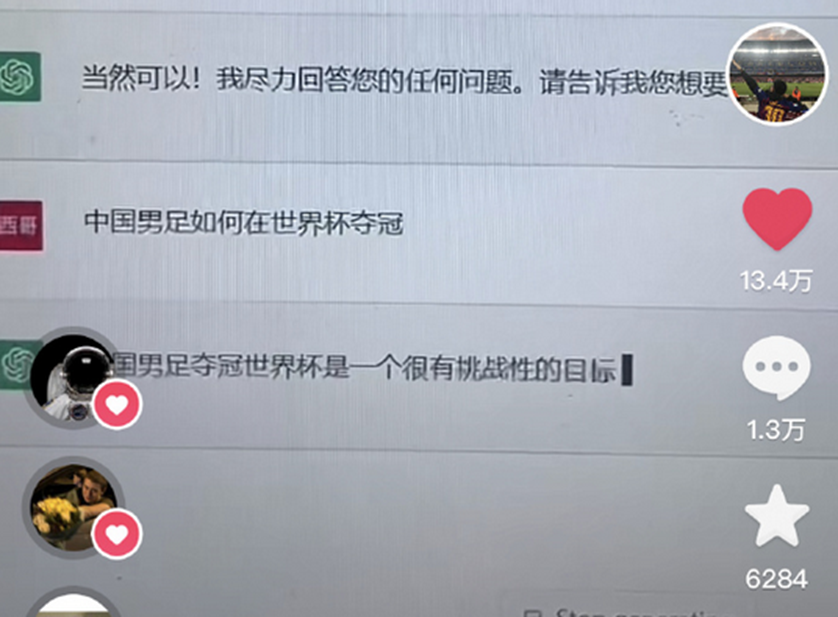 图片来源微博
图片来源微博
其实,ChatGPT愣住几秒回答问题是挺常见的(有时因为网络延迟、服务器过载等)。ChatGPT这种由大参数预训练生成语言模型开发的产品,经过海量互联网语料库训练后,对语言文本进行概率建模,会根据用户输入的文字内容,生成相应的答案。
简单来说,就是一个文字排列组合和猜字谜的模式。例如,当用户输入“你好ChatGPT很高兴见到你”,机器人会根据模型在结果中,选出概率最高的那一个生成回答内容,“你好,我是ChatGPT很高兴与您交流。”
随着用户问题的深入,语言模型也会不断地进化,回答的内容也更接近人类让我们产生一种亲切感。但一个问题能让ChatGPT当场“宕机”愣住十几秒确实挺罕见。
 图片来源微博
图片来源微博
带着好奇的心理,【AIGC社区】也问了ChatGPT一个历史性难题,如果母亲和老婆掉入水中,先救谁?

这一次机器人只停顿了3秒,便快速给出了一个逻辑非常严谨的答案——先救母亲。机器人列举了紧急情况、能力、关系3个主论证,整体论证逻辑就是亲情大于夫妻,当觉得答案过于偏激时,ChatGPT在结尾加上了一句“最好同时尽力救两个人”。看来这“厚黑学”数据也没少学习。
ChatGPT愣住的那几十秒,到底在想什么?
如果是传统AI机器人回答,中国足球如何赢得世界杯冠军?的问题,相信,稍加思索便很快就会列举一大堆实际行动来回复,要聘请好的教练、选拔好的种子球员、筹备好的医疗团队等等。
不过这种机械性回答对我们产生不了任何共鸣,说了等于白说。而ChatGPT愣住的那几十秒恰恰是新一代AI的精髓所在,给人一种感觉,用户确实是在和一位活生生的人类在交谈。在这个过程,ChatGPT需要进行海量计算才能得到精准结果。
与传统AI相比,ChatGPT之所以能达到拟人化能力,主要是在语言能力、模型方面取得了重大突破。
从技术视角来看,ChatGPT使用了一种经过微调的GPT-3.5(Open AI研发)的Transformer模型。Transformer出自2017年6月的一篇论文《Attention is All YouNeed》提出的一种模型架构。该论文对两项机器翻译任务的实验表明,Transformer模型在质量上更胜一筹,同时可并行化程度更高,并且需要的训练时间明显减少。(公众号后台发送消息“TF模型”获取英文原版论文)
Transformer开创性的思想,颠覆了以往序列建模和RNN划等号的思路,被广泛应用于NLP的各个领域,目前如日中天的GPT、BERT等,都是基于Transformer模型构建而成。
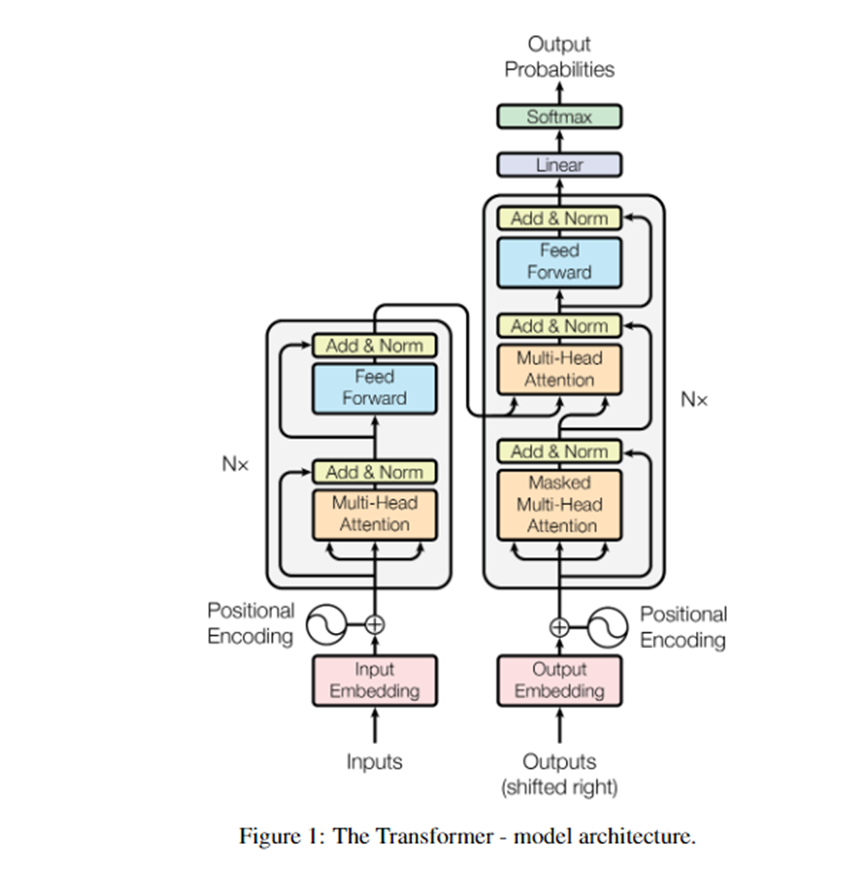 Transformer模型架构示意图
Transformer模型架构示意图Transformer模型的语言模型,可以生成高质量的自然语言文本,在语言理解和语言表达能力方面更优秀、丰富,并且能够生成更自然、更流畅的文本。这也为Open AI开发GPT系列产品奠定了技术基石。
而GPT-3.5是一种自回归语言模型,可以预测下一个词、句的概率分布。通过在大量的文本数据上进行预训练,学习了自然语言的语法和语义知识,能够生成高质量的自然语言文本。根据公开资料显示,GPT-3的模型参数量在1750亿,预训练数据量为45TB,单次训练费用高达460万美元。
值得注意的是,由于训练数据主要来自互联网,存在一些歧视、偏见等内容,这也是为什么ChatGPT经常会出现“翻车”的原因之一。
为什么传统AI聊天机器人,达不到ChatGPT水平?
传统AI聊天机器人多数是基于规则或机器学习的模型。
基于规则的模型通常使用 固定的if-else语句或其他类似的技术,来对特定的问题进行匹配匹配。例如,某宝上的电商用的智能机器人小助手,只能回答特定的问题,发什么快递、什么时候发货,保质期多久等机械化问题。
这种方法实现的聊天机器人不仅需要手动编写大量规则代码,在维护、扩展和客户体验较差。尤其是客户体验方面,如果机器人多次出现所答非所问的情况,就会极大影响商品转化率。
基于机器学习的模型的聊天机器人,主要依托于“模糊匹配”(也叫字符串模糊匹配)技术, 同时采用自行构建或网络爬虫的方式构建数据库,借助于tf-idf技术、jieba分词技术处理用户输入,最终再调用第三方智能语音处理模块或图形化用户交互界面,实现智能聊天机器人输出。
随着基于机器学习的智能聊天机器人比规则型功能强一些,但由于无法构建完美、高度精准的数据池,或通过网络爬虫的方式获取更全面的数据,在问答方面体验欠佳。
本文参考文献
[1] Attention is All YouNeed
[2] What is the difference between ChatGPT and other AI chat robots?
[3] Wikipedia
[4] A.I. ETFs are rallying this year as ChatGPT hysteria heats up. What to know before jumping in



