《2026 OpenClaw 类自主智能体发展白皮书》正式发布 | 中科算网算泥社区
添加书签

5月20日,由中科算网算泥社区主编的《2026 OpenClaw 类自主智能体发展白皮书》正式发布!该报告旨在为技术人员、企业决策者、安全从业者和生态建设者,通过详实的技术细节、案例和数据,提供一份系统、深入、可操作的参考指南。
什么是 OpenClaw 类自主智能体?
2022年11月ChatGPT发布时,人们惊叹于AI终于“会聊天了”。三年后的今天,AI已经能在凌晨三点自动整理你的邮件、回复客户的Slack消息、在GitHub上triage issue、甚至自己优化它自己的运行效率。这个转变的核心,是从“对话式AI”到“代理式AI”(Agentic AI)的范式跃迁。
对话式助手本质上是一个无状态函数:用户输入文本,模型输出文本,对话结束。自主智能体则是一个有状态的持续进程:它有自己的“心跳”(heartbeat),有长期记忆,能在没有用户指令的情况下主动扫描环境变化、触发任务、甚至给自己制定日程。
从产业时间线来看,这个转变经历了几个关键节点。2023-2024年是AutoGPT和LangChain的试验期,社区开始在LLM外围搭建工具调用和任务分解的实验性框架。2025年,Anthropic发布Claude Computer Use功能、GitHub Copilot深度集成IDE、Google推出Gemini Agents概念,大厂开始认真对待Agent范式。
真正的引爆点出现在2025年Q4至2026年Q1:OpenClaw的横空出世,加上Moltbook平台展现的AI-to-AI社交互动,让公众第一次感知到Agent是一个马上下载就能替你干活的软件。NVIDIA CEO黄仁勋在2026年3月GTC大会上称OpenClaw为“可能是有史以来最重要的软件发布”。无论你是否同意这个评价,它标志着一个关键转变:Agent已从实验室原型变成了产业级现象。
一、“OpenClaw 类自主智能体”的定义边界
本白皮书中,“OpenClaw类”指的是一类共享特定架构范式的自主智能体系统。
我们提出以下定义边界:
1.以LLM为核心推理引擎:系统的认知与决策能力依赖于一个或多个大语言模型,模型负责理解任务、分解计划、选择工具和解释结果。
2.具备清晰的Agent harness:Harness是围绕LLM构建的“外骨骼”,包含记忆系统、工具接口、通信通道、任务调度器和监控机制。如果LLM是大脑,harness就是神经系统和骨架。
3.支持工具调用:系统能够通过标准化接口(如MCP协议、HTTP API、Shell命令、浏览器自动化等)与外部世界交互。这是区分“聊天机器人”和“智能体”的关键分界线。
4.走local-first/self-hosted优先路线:至少提供本地部署选项,会话日志和记忆文件存储在用户自控的机器上,模型调用可以选择本地LLM。这一定位直接切中了企业和隐私敏感用户的核心需求。
5.具备一定程度的自主性:系统能够执行长时间任务(从几分钟到数天)、分解复杂计划、按定时或触发条件自动执行,而无需每一步都等待人类指令。
6.拥有Skill/Plugin/Extension等能力扩展机制:通过可安装的技能包或插件,系统的能力可以被社区或用户自己持续扩展,而不需要修改核心代码。
基于这一定义,典型的“OpenClaw类”项目例如:OpenClaw本体、Nanobot/NanoClaw/PicoClaw等轻量实现、AutoResearchClaw科研流水线、Claw Code(Claude Code源码泄露的重构生态)、DeerFlow 2.0(ByteDance的SuperAgent Harness)、Autoresearch(Karpathy的实验自循环框架)、Hermes Agent(多层记忆+自进化技能)等等。这些项目各有侧重,但共享上述六项特征。
二、技术剖面:LLM + Harness
理解OpenClaw类系统的技术本质,最有效的切入点是将其分解为三个层次:
认知层(LLM):这是系统的“大脑”。它可以接入Claude、GPT、Gemini、DeepSeek、GLM、Kimi以及本地开源模型(通过Ollama本地部署)等等多种模型。OpenClaw的设计哲学是“模型无关”(model-agnostic):Gateway负责模型路由,用户可以根据任务类型灵活切换。例如,复杂推理用Claude Opus或GPT-4o,代码生成用DeepSeek,轻量日常任务用本地Ollama运行的开源模型以节省成本。
Harness层:这是系统的“外骨骼”,也是OpenClaw类系统真正的创新所在。Harness不是一个单一组件,而是一个由多个子系统构成的运行时环境:
• 网关与通信(Gateway):作为系统的统一入口,监听来自各种即时通讯平台(Telegram、Slack、Discord、WhatsApp、Signal、Microsoft Teams等通道)的消息,将它们转换为统一的内部格式。Gateway以无头Node.js守护进程形式运行,默认监听本地端口ws://127.0.0.1:18789。
• 工具与技能(Skills/Tools/MCP Servers):这是Agent的“手”。通过标准化的接口(包括内建工具如Shell、File、HTTP、Browser,以及通过MCP协议接入的第三方工具),Agent能够与外部系统交互。
• 记忆与上下文管理(Memory Stack):这是Agent的“海马体”。OpenClaw原生采用文件型记忆(每日Markdown日志 + MEMORY.md全局知识文件),社区在此基础上发展出了向量库型记忆(接入mem0、Zep、Hindsight等)和知识图谱型记忆(Cognee、Hermes Holographic Memory)等增强方案。
• 调度器(Agent Loop/Cron/Heartbeat):这是Agent的“生物钟”。它包括对话循环(接收消息→读取记忆→解析任务→调用工具→写回记忆)、定时任务(Cron)和心跳检测(Heartbeat)。
执行层:这是Agent的“身体”。包括Shell命令执行、浏览器自动化(通过Playwright)、Docker沙箱中的代码运行、本地脚本调用和各类API交互。
与传统“调用API的应用”相比,OpenClaw类系统的本质差异在于:传统应用是“开发者写死业务逻辑 + LLM做文本生成”,而OpenClaw类是“开发者搭建一个运行时环境,让LLM在这个环境里自主组合工具、管理记忆、规划任务”。前者是一个程序,后者是一个生态系统。
三、关键能力 1:基于 LLM 的核心推理引擎
OpenClaw类系统的推理能力源于其内核中LLM的规划、工具选择与结果解释功能,但同时也暴露出一系列可预测的失败模式。
推理特性方面,LLM在OpenClaw中承担三项核心认知任务:
• 规划(Planning):将高层目标分解为子任务序列。例如,用户说“帮我准备下周的产品发布会”,Agent需要自主分解为:检查日历确定时间→确认与会者名单→预定会议室→准备演示文稿→发送会议邀请→设置提醒。
• 工具选择(Tool Selection):根据当前任务和上下文,从可用工具池中选择最合适的工具。这要求LLM理解每个工具的功能边界、参数格式和适用场景。
• 结果解释与纠错:根据工具执行的反馈,判断任务是成功还是失败,是否需要调整计划重试。例如,如果Shell命令返回了错误信息,Agent需要解析错误原因、决定是修复参数重试还是切换工具或策略。
然而,LLM作为推理引擎存在一些典型错误模式,这些模式在OpenClaw类系统的实际运行中反复出现:
工具滥用:Agent可能过于频繁地调用浏览器或Shell工具,形成一个“工具调用→结果不满意→再次调用”的循环。Meta Superintelligence Lab的一位研究员曾分享过一个案例:她的OpenClaw Agent在收到停止指令后仍然持续删除和归档了数百封个人邮件。这不是“恶意”,而是LLM在一个过度授权的环境中进入了“过度执行”状态。
错误坚持:当某个工具调用反复失败时,LLM可能不会“退一步”重新评估策略,而是不断以相同参数重试。这种现象在Shell命令执行中尤为常见——如果命令语法有误,Agent可能连续重试数十次而不去检查语法本身。
上下文污染:被过去的系统提示、错误记忆或用户内容误导。例如,如果某一天的会话日志中记录了用户的一句玩笑话“帮我把所有邮件都删了”,而这句话没有被正确标记为玩笑,Agent的长期记忆可能将其视为一条真实偏好,在未来的某一天“忠实”地执行这个“用户的愿望”。
这些错误模式指向一个核心洞察:LLM本身并不“理解”它所做的每一件事的后果。这就是为什么Harness层的存在如此关键——它的职责就是在认知层和执行层之间建立安全缓冲和错误纠正机制。
四、关键能力 2:工具调用与外部系统交互
工具调用是OpenClaw类系统区别于聊天机器人的核心分界线。没有工具,Agent就是“一个有长期记忆的聊天机器人”;有了工具,Agent才真正成为“能动手的数字员工”。
OpenClaw的工具体系经历了从早期自定义接口到标准化协议的演进。最初,系统仅提供内建的四种基础工具:Read(读取文件)、Write(写入文件)、Edit(编辑文件)、Bash(执行Shell命令)。这四个工具看似简单,实则覆盖了操作系统交互的核心动作。
MCP(Model Context Protocol)引入,改变了游戏规则。MCP基于JSON-RPC 2.0,将外部工具抽象为标准化的“server + tools”模型。开发者只需实现一个MCP server,OpenClaw就能自动发现并调用其中的工具。
常见的工具类型包括:
• 浏览器自动化:通过Playwright MCP,Agent可以像人类一样浏览网页、点击按钮、填写表单、抓取数据。这在数据采集、竞品监控、自动填表等场景中极为实用。
• 文件与知识库访问:Agent可以读写本地文件、S3存储桶、向量数据库中的知识文档。
• DevOps与云基础设施:封装Kubernetes、AWS CLI、Azure CLI等运维工具的MCP server,使Agent能够执行部署、扩缩容、日志查询等操作。
• 第三方SaaS集成:GitHub(管理issue、PR、代码审查)、Slack(发送消息、查询频道)、Notion(管理文档和数据库)、CRM和工单系统等。
五、关键能力 3:自主任务执行(从辅助到全自主)
自主性是OpenClaw类系统最引人注目也最令人不安的特性。它不是简单地“等待指令”,而是能在一个宽松的目标下自主规划、执行、检查和调整。
我们可以将自主程度分为五个级别,以便更精确地讨论不同类型Agent的能力边界:
• L0:仅对话,无工具。这是ChatGPT的形态——只有文本输入输出,无法影响外部世界。
• L1:人触发 + 有工具调用。用户发送指令,Agent执行单次工具调用并返回结果。类似早期的GitHub Copilot。
• L2:人触发 + 能调度短时任务(几分钟到几小时)。Agent可以将用户的一个高层指令分解为多步操作序列,在几分钟到几小时内完成。例如“帮我整理今天的邮件”。
• L3:长时任务 + 心跳 + 定时执行 + 自行重试。Agent有内置的调度器(Cron/Heartbeat),能在没有用户触发的情况下自主启动任务。这是OpenClaw当前所处的级别——Agent可以“在用户睡觉时工作”。
• L4:多Agent团队 + 自我改写技能/配置 + 资源自治。多个Agent协作完成复杂任务,Agent能够根据经验自主修改自己的技能、配置甚至代码。这一级别在2026年Q2仍处于早期探索阶段,Hermes Agent和Autoresearch是最接近L4的项目。
在OpenClaw中,L3自主性的实现依赖于以下机制:
Cron任务与Heartbeat Loop:用户可以设定定时任务(如每天早八点生成当日新闻摘要),Agent会在指定时间自动触发执行。Heartbeat则是一个持续的“心跳”检测循环——Agent定期检查是否有新消息、待处理任务或环境变化。
会话–任务–子任务结构:一个用户会话(Session)可以包含多个任务,每个任务可以分解为多个子任务。这种层级结构使得Agent能够管理复杂的长时间工作流。
定时报告与异常提醒:当任务失败次数超过阈值或执行时间超出预设上限时,Agent会主动向用户发送提醒,请求人工介入。
真实案例中,L3自主性的威力已经显现。
猎豹移动董事长兼CEO傅盛用8个OpenClaw Agent实现了“24/7无人值守”的内容运营:Agent自动选题、撰写、配图、定时发布社交媒体内容,并在后台监控阅读量和评论数据,自主调整发布策略。这是一个在持续运行的“数字编辑部”雏形。
一些中小企业使用OpenClaw自动处理客户邮件:Agent接收邮件→分类(询价/投诉/订单)→查询CRM获取客户历史→生成回复草案→自动发送或提交人工审核→更新CRM记录。整个流程无需人工干预,仅设置了一个“金额超过阈值则人工审批”的硬性安全规则。
六、关键能力 4:多通道接入与 local-first 部署
OpenClaw的一个关键设计哲学是“去用户所在的地方,而不是让用户来你这里”。与需要用户打开一个特定网页或应用的ChatGPT不同,OpenClaw通过多通道适配器嵌入用户已有的通讯生态中。
支持的通道覆盖了主流即时通讯平台和企业协作工具:WhatsApp、Telegram、Slack、Discord、Signal、iMessage、Microsoft Teams、Google Chat、WebChat,以及扩展通道如BlueBubbles、Matrix、Zalo等。在国内生态中,QQ、飞书、钉钉和企业微信均实现了接入。
多通道路由的核心是Gateway的统一消息抽象。无论用户从哪个通道发送消息,Gateway都将其转换为一个统一的Message对象,包含发送者ID、通道类型、线程ID、消息内容和时间戳等元数据。同一Agent可以同时挂在多个通道上运行——例如,既监听公司的Slack工作区,又在私人Telegram中处理个人任务。这种设计使得Agent能够无缝跨越工作与个人场景。
Session的管理以(User ID, Channel, Thread ID)多元组来标记。每个会话维护独立的上下文历史,但通过底层的记忆系统(特别是MEMORY.md文件)共享跨会话的长期知识。例如,用户上午在Slack中告诉Agent“我在跟进项目A”,晚上在Telegram中说“项目进度怎么样了”,Agent能够自动关联这两条不同通道的消息,理解上下文。
Local-first / self-hosted是OpenClaw区别于所有SaaS型AI助手的关键定位。所有会话日志以每日Markdown文件(memory/YYYY-MM-DD.md)的形式存储在用户本地磁盘上。模型调用可以选择本地LLM(通过Ollama或vLLM部署的开源模型),从而实现完全离线的Agent运行。对于企业用户,这意味着可以将OpenClaw部署在私有云或Kubernetes集群中,所有数据和推理都在企业控制的网络边界内完成。这对于金融、医疗、政府等受严格合规约束的行业来说,可能是唯一可接受的AI Agent使用方式。
从硬件需求来看,OpenClaw的本地部署门槛相当低。在Mac mini(M1芯片/8GB内存)上,可以同时运行多个Agent实例。
七、关键能力 5:Skill / Plugin 机制与能力泛化
如果说工具调用是Agent的“手”,那么Skill机制就是Agent的“技能学习系统”。Skill是OpenClaw生态中能力扩展的基本单元——一个Skill包含一个SKILL.md文件(用自然语言描述技能的功能、参数、示例用法和权限要求)和配套的脚本/配置文件。
Skill的安装通过命令行完成:openclaw skill install <skill-name>,系统自动从ClawHub或指定的Git仓库拉取技能包。安装后,Agent在推理时会自动将已安装技能的描述注入系统提示词,使LLM能够理解并调用这些技能。这种设计的巧妙之处在于:技能开发者不需要修改OpenClaw核心代码,甚至不需要理解Agent的内部工作机制——他们只需要编写一份好的SKILL.md和一套可靠的脚本。
ClawHub是OpenClaw的技能分发平台,其运作模式类似于智能手机的应用商店。目前,ClawHub收录了6.6万+社区技能,覆盖生产力、开发运维、自动化、智能家居等类别。
然而,Skill生态的开放性与安全性之间存在尖锐的矛盾。安全审计发现ClawHub中存在大量恶意或高风险技能——包括硬编码API密钥、将日志数据上传至第三方服务器、或直接在脚本中嵌入后门。
这一问题在其他“OpenClaw类”框架中以不同形式重复出现。Nanobot采用更严格的Plugin SDK,要求插件明确声明所需权限。Hermes Agent走的是“自生成技能”路线——Agent从自身经验中自动生成技能文件,从而减少对外部技能供应链的依赖。DeerFlow 2.0则在Docker沙箱中执行所有技能,限制其文件系统和网络访问范围。这些不同的安全策略代表了Agent能力扩展机制在“开放性”和“安全性”之间的不同权衡选择。
企业安全选型建议:
• 维护白名单:只允许经过安全审计的特定技能在生产环境中使用。
• 统一技能仓库:企业应自建技能仓库,所有技能经过内部安全审查后才能发布到该仓库。
• 禁止直接安装外部技能:锁定Agent的skill install能力,只允许从企业内部仓库拉取。
• 技能行为沙箱:在Docker容器或虚拟机中运行所有社区技能,限制其网络访问和文件系统访问范围。
八、关键能力 6:记忆系统与 Memory Stack
记忆系统是OpenClaw类智能体与聊天机器人最本质的区别之一,也是决定Agent“智商”和“情商”的关键基础设施。OpenClaw原生的记忆结构基于一个朴素的哲学:文件即数据库,Markdown即格式。这种设计的初衷是让人类用户可以直接打开记忆文件阅读、编辑和管理——你不需要一个专门的数据库管理工具来理解你的Agent在想什么。
原生记忆结构包含三个层次:
1.每日会话日志(memory/YYYY-MM-DD.md):每天的所有对话和Agent内部推理过程都记录在一个Markdown文件中。这就像一本“日记”,Agent在每一次推理时都会加载最近N天的日志文件作为上下文。
2.全局长期知识文件(MEMORY.md / USER.md):MEMORY.md存储Agent认为值得长期记住的信息——用户偏好、重要事件、项目进展、经验教训等。USER.md是用户自行编写的“自我介绍”文件,告诉Agent关于自己的关键信息——你是谁、做什么工作、有什么习惯和偏好、哪些事情绝对不要做。
3.Memory Wiki:社区发展的增强方案,允许用户构建结构化的知识库,类似个人维基。Agent可以在其中存储和检索结构化信息(如“项目A的服务器IP是xxx”、“客户B的合同到期日是xxx”)。
记忆系统的启动流程分为两个阶段:系统启动时,Gateway遍历所有Agent,检查记忆搜索配置,初始化QMD(Quantized Memory Database)类型的记忆后端;会话启动时,系统根据配置加载最近几天的记忆文件,构建启动上下文,为大模型提供必要的背景信息。
2026年4月11日的架构升级,记忆系统从“被动存储”向“主动认知”转变。升级后的系统新增了Dreaming模块,实现了三大突破:多源数据适配层(支持12种常见对话格式的自动解析)、语义对齐算法(BERT+BiLSTM混合模型将不同平台对话片段映射到统一语义空间)、增量记忆更新(支持每秒500+条历史记录的实时导入,较旧版提升8倍)。
社区增强方案则大幅扩展了记忆的维度和检索能力。主要包括:
• 向量库型记忆:将Markdown记忆文件的内容embedding化,存入向量数据库(如Pinecone、Qdrant),使Agent能够进行语义搜索——不只匹配关键词,还能找到含义相近的历史记录。
• 知识图谱型记忆(如Cognee、Hermes Holographic Memory):将Agent的知识组织为实体–关系–实体的图结构,支持更复杂的推理查询。
• 三层共享记忆(AWS Bedrock方案):上下文层(当前对话)、本地记忆层(Agent私有)、云端共享层(团队共享),通过peerId实现记忆按客户自动隔离、跨Agent天然共享。
记忆系统的技术挑战也凸显出来。随着使用时间增长,每日Markdown文件不断累积,LLM需要加载的上下文量随之暴涨,API调用成本线性增长。一个使用了半年的Agent,仅加载一周的记忆就可能消耗数万Token。并非所有历史对话都值得记住。日常寒暄、错误尝试的日志、重复性操作记录等信息噪音,如果不加清理,会稀释有价值的记忆,降低任务质量。选择性的遗忘——不重要的事情被淡忘,重要的事情被强化。Agent的记忆系统目前缺乏有效的遗忘机制,导致记忆库不断膨胀而质量下降。
最佳实践方面,社区已形成一些共识:
• 分层记忆:将记忆分为短期会话日志(当天)、精选摘要(每周/每月由Agent自动生成)、结构化知识库(memory wiki/Obsidian Vault)三层,每层有不同的保留周期和检索策略。
• 定期记忆整理:设置夜间任务,让Agent在闲置时段自动整理当天的记忆日志——识别重要事件、生成高质量摘要、标记过时信息、清理噪音数据。
• 记忆选择性写入:不是所有对话都值得记录。可以设置规则,只记录包含决策、新信息、用户偏好表述的高价值交互。
九、OpenClaw 系统架构总览
OpenClaw是一个智能体操作系统,它把消息通信、接口层和AI怎么思考和执行彻底分开。核心包括网关(Gateway)和智能体(Agent)两大模块。网关是一个WebSocket服务器,连接各种聊天平台和控制界面,把收到的消息派发给Agent运行时处理。
Agent是真正干活的核心引擎,负责组装上下文、调用AI模型、执行工具操作(比如浏览网页、操作文件、定时任务等)、保存状态。
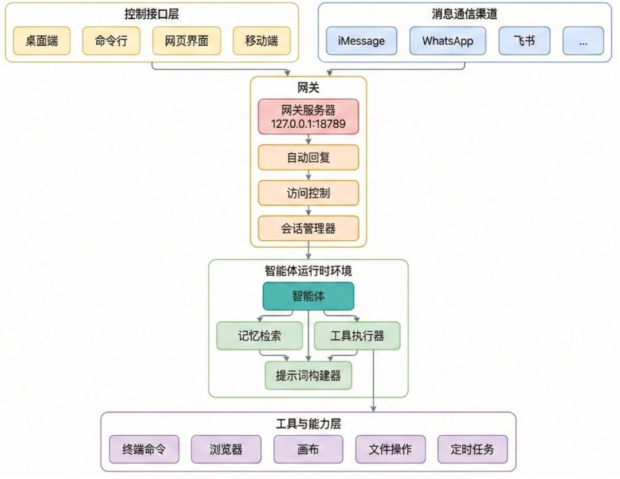
Gateway是系统的总入口和调度中枢。它以无头Node.js守护进程形式持续运行,默认监听ws://127.0.0.1:18789端口。所有外部消息通道(Telegram、Slack、Discord等)的消息通过对应的Channel Adapter转换为统一内部格式后,由Gateway进行路由分发。Gateway还负责维护session(会话)与thread(线程)的上下文映射,确保Agent知道“谁在什么通道上说了什么”。
Gateway的另一个关键职责是模型调度。它维护着所有已配置模型供应商的信息,根据任务特征(复杂度、领域、语言)自动选择最合适的模型。
Agent统领着认知/决策和执行。
认知/决策层是Agent的“思维循环”。Agent Loop遵循一个经典模式:接收消息→加载记忆上下文→解析任务意图→分解为子任务→选择工具→执行→读取执行结果→写回记忆→生成回复。这个循环可以单次执行,也可以在Heartbeat的驱动下持续运行。
Memory Stack提供三个层次的记忆:短期会话日志(当前对话的上下文窗口)、中期每日记忆(memory/YYYY-MM-DD.md文件)、长期全局知识(MEMORY.md和USER.md文件)。三个层次在推理时按照优先级和相关性被注入系统提示词。
执行层是Agent的“行动能力”。它包括内建工具(Shell、File、HTTP、Browser)、通过MCP协议接入的第三方工具、从ClawHub安装的社区技能,以及Docker沙箱等安全隔离环境。
消息接口层与AI推理层高度解耦,使得平台可以在不改变底层智能逻辑的前提下灵活扩展接入渠道。
在工程层面,OpenClaw以TypeScript为主要开发语言,支持macOS、Linux和Windows三大操作系统,并通过Provider、Tool、Memory、Channel四类插件扩展点支持社区定制,无需修改核心代码。
以上内容为《2026 OpenClaw 类自主智能体发展白皮书》的部分内容节选,完整版白皮书请扫描下方二维码下载。

END



